OSMI
Overview
We explore the relationship between certain network configurations and the performance of distributed Machine Learning systems. We build upon the Open Surrogate Model Inference (OSMI) Benchmark, a distributed inference benchmark for analyzing the performance of machine-learned surrogate models developed by Wes Brewer et. Al. We focus on analyzing distributed machine-learning systems, via machine-learned surrogate models, across varied hardware environments. By deploying the OSMI Benchmark on platforms like Rivanna HPC, WSL, and Ubuntu, we offer a comprehensive study of system performance under different configurations. The paper presents insights into optimizing distributed machine learning systems, enhancing their scalability and efficiency. We also develope a framework for automating the OSMI benchmark.
Introdcution
With the proliferation of machine learning as a tool for science, the need for efficient and scalable systems is paramount. This paper explores the Open Surrogate Model Inference (OSMI) Benchmark, a tool for testing the performance of machine-learning systems via machine-learned surrogate models. The OSMI Benchmark, originally created by Wes Brewer and colleagues, serves to evaluate various configurations and their impact on system performance.
Our research pivots around the deployment and analysis of the OSMI Benchmark across various hardware platforms, including the high-performance computing (HPC) system Rivanna, Windows Subsystem for Linux (WSL), and Ubuntu environments.
In each experiment, there are a variable number of TensorFlow model server instances, overseen by a HAProxy load balancer that distributes inference requests among the servers. Each server instance operates on a dedicated GPU, choosing between the V100 or A100 GPUs available on Rivanna. This setup mirrors real-world scenarios where load balancing is crucial for system efficiency.
On the client side, we initiate a variable number of concurrent clients executing the OSMI benchmark to simulate different levels of system load and analyze the corresponding inference throughput.
On top of the original OSMI-Bench, we implemented an object-oriented interface in Python for running experiments with ease, streamlining the process of benchmarking and analysis. The experiments rely on custom-built images based on NVIDIA’s tensorflow image. The code works on several hardwares, assuming the proper images are built.
Additionally, We develop a script for launching simultaneous experiments with permutations of pre-defined parameters with Cloudmesh Experiment-Executor. The Experiment Executor is a tool that automates the generation and execution of experiment variations with different parameters. This automation is crucial for conducting tests across a spectrum of scenarios.
Finally, we analyze the inference throughput and total time for each experiment. By graphing and examining these results, we draw critical insights into the performance dynamics of distributed machine learning systems.
In summary, a comprehensive examination of the OSMI Benchmark in diverse distributed ML systems is provided. We aim to contribute to the optimization of these systems, by providing a framework for finding the best performant system configuration for a given use case. Our findings pave the way for more efficient and scalable distributed computing environments.
The architectural view of the benchmarks are depictued in Figure 1 and Figure 2.
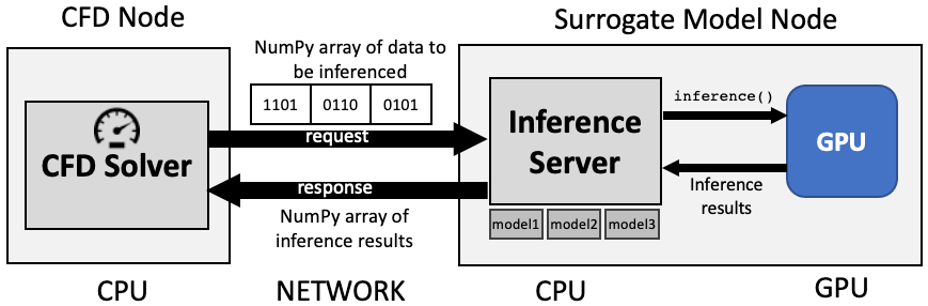
Figure 1: Surrogate calculations via a Inference Server.
Figure 2: Possible benchmark configurations to measure sped of parallel iference.
References
Brewer, Wesley, Daniel Martinez, Mathew Boyer, Dylan Jude, Andy Wissink, Ben Parsons, Junqi Yin, and Valentine Anantharaj. “Production Deployment of Machine-Learned Rotorcraft Surrogate Models on HPC.” In 2021 IEEE/ACM Workshop on Machine Learning in High Performance Computing Environments (MLHPC), pp. 21-32. IEEE, 2021, https://ieeexplore.ieee.org/abstract/document/9652868, Note that OSMI-Bench differs from SMI-Bench described in the paper only in that the models that are used in OSMI are trained on synthetic data, whereas the models in SMI were trained using data from proprietary CFD simulations. Also, the OSMI medium and large models are very similar architectures as the SMI medium and large models, but not identical. ↩︎
Brewer, Wesley, Greg Behm, Alan Scheinine, Ben Parsons, Wesley Emeneker, and Robert P. Trevino. “iBench: a distributed inference simulation and benchmark suite.” In 2020 IEEE High Performance Extreme Computing Conference (HPEC), pp. 1-6. IEEE, 2020. ↩︎
Brewer, Wesley, Greg Behm, Alan Scheinine, Ben Parsons, Wesley Emeneker, and Robert P. Trevino. “Inference benchmarking on HPC systems.” In 2020 IEEE High Performance Extreme Computing Conference (HPEC), pp. 1-9. IEEE, 2020. ↩︎
Brewer, Wesley, Chris Geyer, Dardo Kleiner, and Connor Horne. “Streaming Detection and Classification Performance of a POWER9 Edge Supercomputer.” In 2021 IEEE High Performance Extreme Computing Conference (HPEC), pp. 1-7. IEEE, 2021. ↩︎
Gregor von Laszewski, J. P. Fleischer, and Geoffrey C. Fox. 2022. Hybrid Reusable Computational Analytics Workflow Management with Cloudmesh. https://doi.org/10.48550/ARXIV.2210.16941 ↩︎