Introduction
The Surrogate Benchmark Initiative (SBI) project will create a community repository and FAIR data ecosystem for HPC application surrogate benchmarks, including data, code, and all relevant collateral artifacts the science and engineering community needs to use and reuse these data sets and surrogates.
Like nearly every field of science and engineering today, Computational Science using High Performance Computing (HPC) is being transformed by the ongoing revolution in Artificial Intelligence (AI), especially by the use of data-driven Deep Neural Network (DNN) techniques. In particular, DNN surrogate models 1 2 3, are being used to replace either part or all of traditional large-scale HPC simulations, achieving remarkable performance improvements (e.g., several orders of magnitude) in the process 4 5 6 7 8. Having been trained on data produced by actual runs of a given HPC simulation, such a surrogate can imitate, with high fidelity, part or all of that simulation, producing the same outcomes for a given set of inputs, but at far less cost in time and energy.
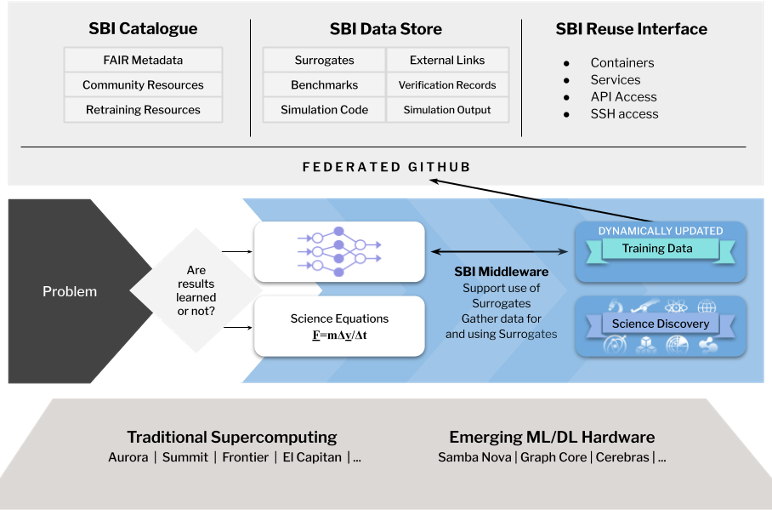
Figure 1. The Surrogate Benchmark Initiative (SBI)and its components
As a world leader in HPC for many decades, the Department of Energy will undoubtedly seek to exploit the power of such AI-driven surrogates, especially because of the end of Dennard scaling and Moore’s law. However, at present, there are no accepted benchmarks for such surrogates, and so no way to measure progress or inform the codesign of new HPC systems to support their use. The Surrogate Benchmark Initiative (SBI) project proposed below aims to address this fundamental problem by creating a community repository and FAIR data ecosystem for HPC application surrogate benchmarks, including data, code, and all relevant collateral artifacts the science and engineering community needs to use and reuse these data sets and surrogates.
To make “… scientific data publicly available to the AI community so that algorithms, tools, and techniques work for science,” we propose a community-driven, FAIR benchmarking activity that will 1) support AI research into different attractive approaches and 2) provide exemplars with reference implementations that will enable surrogates to be extended across a wide range of scientific fields, while encompassing the many different aspects of simulation where surrogates are useful. The key components of the project are depicted in Figure 1 above.
By collaborating with the major industry organization in this area - MLPerf and mirroring their process as much as possible, we will both increase the value of and obtain industry involvement in the SBI benchmarks. MLPerf has over 80 institutional members (mainly from industry) and strong existing involvement of the Department of Energy laboratories through the HPC working group inside MLPerf, which is now being extended with a science data working group. To ensure that FAIR principles are rigorously followed, we will initially set up data and model repositories outside MLPerf. Containers and service specifications such as OpenAPI will be systematically used. We will then explore how much can be usefully and FAIRly integrated with MLPerf, as our repositories have related but different goals and constraints from MLPerf. To learn how to effectively and efficiently set up FAIR repositories, we will start with (updates of) existing surrogates from team members.
Simultaneously, we will reach out to the community of experienced users building on our recent review 2 and recent papers 4, 9, 10. The outreach will use permanent SBI working groups with the Zoom/Meet/Teams/BlueJeans/Slack/cloud support that is now common and these will link to appropriate MLPerf groups. Online tutorials will be constructed based on the data and AI models that will support the broad understanding of the use and design of surrogates. These tutorials will also be designed so that they can help other stakeholders that need to understand the value of and requirements for surrogates; this includes the systems software/middleware and hardware architecture communities. The tutorials will be an early goal so we can reach out to domain scientists with important simulation codes but so far little or unsophisticated surrogate use.
A key aspect of SBI will be the development of an efficient generic surrogate architecture and accompanying middleware that will support the derivation and use of surrogates across many fields. Another specific activity will be the support of the use of benchmarks in the uncertainty quantification of the surrogate estimates. Thirdly there will be important studies of the amount of training data needed to get reliable surrogates for a given accuracy choice. We have already developed an effective performance model for surrogates but this needs extension as deeper uses of surrogates become understood and populated in our repositories.
We will link the repositories to important hardware systems including major DoE and NSF environments, commercial high-performance clouds, and available novel hardware. The study of the emerging AI systems space is an important goal of our project as our benchmarks stress both AI and simulation performance and so may not give the same conclusions as purely AI-focused benchmarks. Although we initially stress simulation surrogates, we will also consider AI surrogates for big data computations.
We intend that our repositories will generate active research from both the participants in our project and the broad community of AI and domain scientists. The FAIR ease of use, tutorials, and links to relevant execution platforms will be important. To initiate and foster strong virtual community support we will also use hackathons, Meetups, journal special issues, conference tutorials, and exhibits to nurture the outside use of our resources. As well as advancing research, which is our focus, we expect the project will be valuable for education and training. The project will explicitly fund staff to make sure that non-project users are properly supported and that our use of FAIR principles is effective.
Refernces
Geoffrey Fox, Shantenu Jha, “Understanding ML driven HPC: Applications and Infrastructure,” in IEEE eScience 2019 Conference, San Diego, California [Online]. Available: https://escience2019.sdsc.edu/ ↩︎
Geoffrey Fox, Shantenu Jha, “Learning Everywhere: A Taxonomy for the Integration of Machine Learning and Simulations,” in IEEE eScience 2019 Conference, San Diego, California [Online]. Available: https://arxiv.org/abs/1909.13340 ↩︎ ↩︎
Geoffrey Fox, James A. Glazier, JCS Kadupitiya, Vikram Jadhao, Minje Kim, Judy Qiu, James P. Sluka, Endre Somogyi, Madhav Marathe, Abhijin Adiga, Jiangzhuo Chen, Oliver Beckstein, and Shantenu Jha, “Learning Everywhere: Pervasive Machine Learning for Effective High-Performance Computation,” in HPDC Workshop at IPDPS 2019, Rio de Janeiro, 2019 [Online]. Available: https://arxiv.org/abs/1902.10810, http://dsc.soic.indiana.edu/publications/Learning_Everywhere_Summary.pdf ↩︎
M. F. Kasim, D. Watson-Parris, L. Deaconu, S. Oliver, P. Hatfield, D. H. Froula, G. Gregori, M. Jarvis, S. Khatiwala, J. Korenaga, J. Topp-Mugglestone, E. Viezzer, and S. M. Vinko, “Up to two billion times acceleration of scientific simulations with deep neural architecture search,” arXiv [stat.ML], 17-Jan-2020 [Online]. Available: http://arxiv.org/abs/2001.08055 ↩︎ ↩︎
JCS Kadupitiya , Geoffrey C. Fox , and Vikram Jadhao, “Machine learning for performance enhancement of molecular dynamics simulations,” in International Conference on Computational Science ICCS2019, Faro, Algarve, Portugal, 2019 [Online]. Available: http://dsc.soic.indiana.edu/publications/ICCS8.pdf ↩︎
A. Moradzadeh and N. R. Aluru, “Molecular Dynamics Properties without the Full Trajectory: A Denoising Autoencoder Network for Properties of Simple Liquids,” J. Phys. Chem. Lett., vol. 10, no. 24, pp. 7568–7576, Dec. 2019 [Online]. Available: http://dx.doi.org/10.1021/acs.jpclett.9b02820 ↩︎
Y. Sun, R. F. DeJaco, and J. I. Siepmann, “Deep neural network learning of complex binary sorption equilibria from molecular simulation data,” Chem. Sci., vol. 10, no. 16, pp. 4377–4388, Apr. 2019 [Online]. Available: http://dx.doi.org/10.1039/c8sc05340e ↩︎
F. Häse, I. Fdez Galván, A. Aspuru-Guzik, R. Lindh, and M. Vacher, “How machine learning can assist the interpretation of ab initio molecular dynamics simulations and conceptual understanding of chemistry,” Chem. Sci., vol. 10, no. 8, pp. 2298–2307, Feb. 2019 [Online]. Available: http://dx.doi.org/10.1039/c8sc04516j ↩︎
O. Obiols-Sales, A. Vishnu, N. Malaya, and A. Chandramowlishwaran, “CFDNet: a deep learning-based accelerator for fluid simulations,” arXiv [physics.flu-dyn]. 2020 [Online]. Available: http://arxiv.org/abs/2005.04485 ↩︎
J. A. Tallman, M. Osusky, N. Magina, and E. Sewall, “An Assessment of Machine Learning Techniques for Predicting Turbine Airfoil Component Temperatures, Using FEA Simulations for Training Data,” in ASME Turbo Expo 2019: Turbomachinery Technical Conference and Exposition, 2019 [Online]. Available: https://asmedigitalcollection.asme.org/GT/proceedings-abstract/GT2019/58646/V05AT20A002/1066873. [Accessed: 23-Feb-2020] ↩︎