A list of documents managed through the Web Site related to this project.
This is the multi-page printable view of this section. Click here to print.
Documentation
- 1: Abstract
- 2: Introduction
- 3: Metadata Subgroup
- 4: Publications
- 5: Team
- 6: Surrogates
- 6.1: AutoPhaseNN: unsupervised physics-aware deep learning of 3D nanoscale Bragg coherent diffraction imaging
- 6.2: Calorimeter surrogates
- 6.3: Virtual tissue
- 6.4: Cosmoflow
- 6.5: Fully ionized plasma fluid model closures
- 6.6: Ions in nanoconfinement
- 6.7: miniWeatherML
- 6.8: OSMI
- 6.9: Particle dynamics
- 6.10: PtychoNN: deep learning network for ptychographic imaging that predicts sample amplitude and phase from diffraction data.
- 7: Software
- 8: Meeting Notes
- 8.1: Poster
- 8.2: Links
- 8.3: Meeting Notes 02-05-2024
- 8.4: Meeting Notes 01-08-2024
- 8.5: Meeting Notes 10-30-2023
- 8.6: Meeting Notes 09-25-2023
- 8.7: Meeting Notes 08-25-2023
- 8.8: Meeting Notes 07-31-2023
- 8.9: Meeting Notes 06-26-2023
- 8.10: Meeting Notes 05-29-2023
- 8.11: Meeting Notes 04-03-2023
- 8.12: Meeting Notes 02-27-2023
- 8.13: Meeting Notes 01-30-2023
- 8.14: Meeting Notes 01-05-2023
- 8.15: Meeting Notes 11-28-2022
- 8.16: Meeting Notes 10-31-2022
- 8.17: Meeting Notes 09-26-2022
- 8.18: Meeting Notes 08-15-2022
- 8.19: Meeting Notes 06-27-2022
- 8.20: Meeting Notes 05-23-2022
- 8.21: Meeting Notes 04-25-2022
- 8.22: Meeting Notes 03-19-2022
- 8.23: Meeting Notes 02-14-2022
- 8.24: Meeting Notes 01-10-2022
- 8.25: Meeting Notes 10-21-2021
- 8.26: Meeting Notes 09-27-2021
- 8.27: Meeting Notes 08-30-2021
- 8.28: Meeting Notes 07-26-2021
- 8.29: Meeting Notes 06-29-2021
- 8.30: Meeting Notes 05-24-2021
- 8.31: Meeting Notes 04-19-2021
- 8.32: Meeting Notes 03-23-2021
- 8.33: Meeting Notes 02-20-2021
- 8.34: Meeting Notes 01-20-2021
- 9: Contribution Guidelines
1 - Abstract
A brief abstract about the project
The Surrogate Benchmark Initiative (SBI) abstract as presented at the DOE ASCR Meeting, Feb 2024
Replacing traditional HPC computations with deep learning surrogates can dramatically improve the performance of simulations. We need to build repositories for AI models, datasets, and results that are easily used with FAIR metadata. These must cover a broad spectrum of use cases and system issues. The need for heterogeneous architectures means new software and performance issues. Further surrogate performance models are needed. The SBI (Surrogate Benchmark Initiative) collaboration between Argonne National Lab, Indiana University, Rutgers, University of Tennessee, and Virginia (lead) with MLCommons addresses these issues. The collaboration accumulates existing and generates new surrogates and hosts them (a total of around 20) in repositories. Selected surrogates become MLCommons benchmarks. The surrogates are managed by a FAIR metadata system, SABATH, developed by Tennessee and implemented for our repositories by Virginia.
The surrogate domains are Bragg coherent diffraction imaging, ptychographic imaging, Fully ionized plasma fluid model closures, molecular dynamics(2),
turbulence in computational fluid dynamics, cosmology, Kaggle calorimeter challenge(4), virtual tissue simulations(2), and performance tuning. Rutgers built a taxonomy using previous work and protein-ligand docking, which will be quantified using six mini-apps representing the system structure for different surrogate uses. Argonne has studied the data-loading and I/O structure for deep learning using inter-epoch and intra-batch reordering to improve data reuse. Their system addresses communication with the aggregation of small messages. They also study second-order optimizers using compression balancing accuracy and compression level. Virginia has used I/O parallelization to further improve performance. Indiana looked at ways of reducing the needed training set size for a given surrogate accuracy.1,2,3
Refernces
Web Page for Surrogate Benchmark Initiative SBI: FAIR Surrogate Benchmarks Supporting AI and Simulation Research. Web Page, January 2024. URL: https://sbi-fair.github.io/. ↩︎
Publications: https://sbi-fair.github.io/docs/publications/ ↩︎
Meeting summaries: https://docs.google.com/document/d/1cqMOkV9Cag6EB6HI6fR20gwhVwUeG5yijtJ3aEW0Crs/ ↩︎
2 - Introduction
A brief introduction to the project
The Surrogate Benchmark Initiative (SBI) project will create a community repository and FAIR data ecosystem for HPC application surrogate benchmarks, including data, code, and all relevant collateral artifacts the science and engineering community needs to use and reuse these data sets and surrogates.
Like nearly every field of science and engineering today, Computational Science using High Performance Computing (HPC) is being transformed by the ongoing revolution in Artificial Intelligence (AI), especially by the use of data-driven Deep Neural Network (DNN) techniques. In particular, DNN surrogate models 1 2 3, are being used to replace either part or all of traditional large-scale HPC simulations, achieving remarkable performance improvements (e.g., several orders of magnitude) in the process 4 5 6 7 8. Having been trained on data produced by actual runs of a given HPC simulation, such a surrogate can imitate, with high fidelity, part or all of that simulation, producing the same outcomes for a given set of inputs, but at far less cost in time and energy.
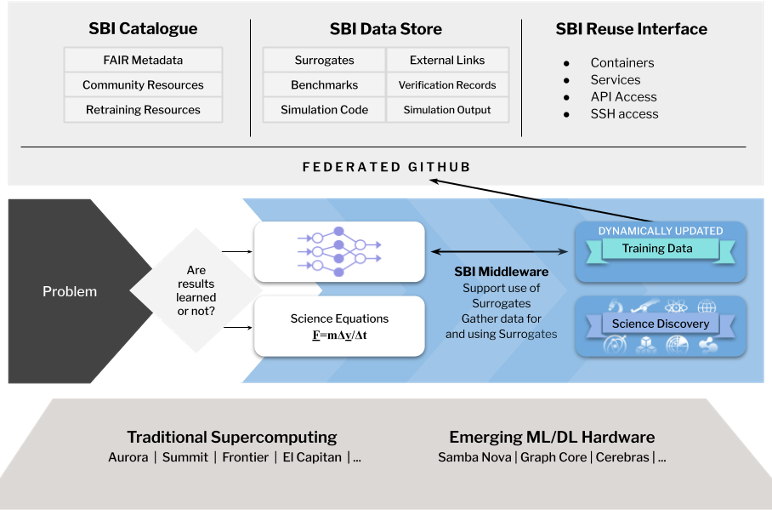
Figure 1. The Surrogate Benchmark Initiative (SBI)and its components
As a world leader in HPC for many decades, the Department of Energy will undoubtedly seek to exploit the power of such AI-driven surrogates, especially because of the end of Dennard scaling and Moore’s law. However, at present, there are no accepted benchmarks for such surrogates, and so no way to measure progress or inform the codesign of new HPC systems to support their use. The Surrogate Benchmark Initiative (SBI) project proposed below aims to address this fundamental problem by creating a community repository and FAIR data ecosystem for HPC application surrogate benchmarks, including data, code, and all relevant collateral artifacts the science and engineering community needs to use and reuse these data sets and surrogates.
To make “… scientific data publicly available to the AI community so that algorithms, tools, and techniques work for science,” we propose a community-driven, FAIR benchmarking activity that will 1) support AI research into different attractive approaches and 2) provide exemplars with reference implementations that will enable surrogates to be extended across a wide range of scientific fields, while encompassing the many different aspects of simulation where surrogates are useful. The key components of the project are depicted in Figure 1 above.
By collaborating with the major industry organization in this area - MLPerf and mirroring their process as much as possible, we will both increase the value of and obtain industry involvement in the SBI benchmarks. MLPerf has over 80 institutional members (mainly from industry) and strong existing involvement of the Department of Energy laboratories through the HPC working group inside MLPerf, which is now being extended with a science data working group. To ensure that FAIR principles are rigorously followed, we will initially set up data and model repositories outside MLPerf. Containers and service specifications such as OpenAPI will be systematically used. We will then explore how much can be usefully and FAIRly integrated with MLPerf, as our repositories have related but different goals and constraints from MLPerf. To learn how to effectively and efficiently set up FAIR repositories, we will start with (updates of) existing surrogates from team members.
Simultaneously, we will reach out to the community of experienced users building on our recent review 2 and recent papers 4, 9, 10. The outreach will use permanent SBI working groups with the Zoom/Meet/Teams/BlueJeans/Slack/cloud support that is now common and these will link to appropriate MLPerf groups. Online tutorials will be constructed based on the data and AI models that will support the broad understanding of the use and design of surrogates. These tutorials will also be designed so that they can help other stakeholders that need to understand the value of and requirements for surrogates; this includes the systems software/middleware and hardware architecture communities. The tutorials will be an early goal so we can reach out to domain scientists with important simulation codes but so far little or unsophisticated surrogate use.
A key aspect of SBI will be the development of an efficient generic surrogate architecture and accompanying middleware that will support the derivation and use of surrogates across many fields. Another specific activity will be the support of the use of benchmarks in the uncertainty quantification of the surrogate estimates. Thirdly there will be important studies of the amount of training data needed to get reliable surrogates for a given accuracy choice. We have already developed an effective performance model for surrogates but this needs extension as deeper uses of surrogates become understood and populated in our repositories.
We will link the repositories to important hardware systems including major DoE and NSF environments, commercial high-performance clouds, and available novel hardware. The study of the emerging AI systems space is an important goal of our project as our benchmarks stress both AI and simulation performance and so may not give the same conclusions as purely AI-focused benchmarks. Although we initially stress simulation surrogates, we will also consider AI surrogates for big data computations.
We intend that our repositories will generate active research from both the participants in our project and the broad community of AI and domain scientists. The FAIR ease of use, tutorials, and links to relevant execution platforms will be important. To initiate and foster strong virtual community support we will also use hackathons, Meetups, journal special issues, conference tutorials, and exhibits to nurture the outside use of our resources. As well as advancing research, which is our focus, we expect the project will be valuable for education and training. The project will explicitly fund staff to make sure that non-project users are properly supported and that our use of FAIR principles is effective.
Refernces
Geoffrey Fox, Shantenu Jha, “Understanding ML driven HPC: Applications and Infrastructure,” in IEEE eScience 2019 Conference, San Diego, California [Online]. Available: https://escience2019.sdsc.edu/ ↩︎
Geoffrey Fox, Shantenu Jha, “Learning Everywhere: A Taxonomy for the Integration of Machine Learning and Simulations,” in IEEE eScience 2019 Conference, San Diego, California [Online]. Available: https://arxiv.org/abs/1909.13340 ↩︎ ↩︎
Geoffrey Fox, James A. Glazier, JCS Kadupitiya, Vikram Jadhao, Minje Kim, Judy Qiu, James P. Sluka, Endre Somogyi, Madhav Marathe, Abhijin Adiga, Jiangzhuo Chen, Oliver Beckstein, and Shantenu Jha, “Learning Everywhere: Pervasive Machine Learning for Effective High-Performance Computation,” in HPDC Workshop at IPDPS 2019, Rio de Janeiro, 2019 [Online]. Available: https://arxiv.org/abs/1902.10810, http://dsc.soic.indiana.edu/publications/Learning_Everywhere_Summary.pdf ↩︎
M. F. Kasim, D. Watson-Parris, L. Deaconu, S. Oliver, P. Hatfield, D. H. Froula, G. Gregori, M. Jarvis, S. Khatiwala, J. Korenaga, J. Topp-Mugglestone, E. Viezzer, and S. M. Vinko, “Up to two billion times acceleration of scientific simulations with deep neural architecture search,” arXiv [stat.ML], 17-Jan-2020 [Online]. Available: http://arxiv.org/abs/2001.08055 ↩︎ ↩︎
JCS Kadupitiya , Geoffrey C. Fox , and Vikram Jadhao, “Machine learning for performance enhancement of molecular dynamics simulations,” in International Conference on Computational Science ICCS2019, Faro, Algarve, Portugal, 2019 [Online]. Available: http://dsc.soic.indiana.edu/publications/ICCS8.pdf ↩︎
A. Moradzadeh and N. R. Aluru, “Molecular Dynamics Properties without the Full Trajectory: A Denoising Autoencoder Network for Properties of Simple Liquids,” J. Phys. Chem. Lett., vol. 10, no. 24, pp. 7568–7576, Dec. 2019 [Online]. Available: http://dx.doi.org/10.1021/acs.jpclett.9b02820 ↩︎
Y. Sun, R. F. DeJaco, and J. I. Siepmann, “Deep neural network learning of complex binary sorption equilibria from molecular simulation data,” Chem. Sci., vol. 10, no. 16, pp. 4377–4388, Apr. 2019 [Online]. Available: http://dx.doi.org/10.1039/c8sc05340e ↩︎
F. Häse, I. Fdez Galván, A. Aspuru-Guzik, R. Lindh, and M. Vacher, “How machine learning can assist the interpretation of ab initio molecular dynamics simulations and conceptual understanding of chemistry,” Chem. Sci., vol. 10, no. 8, pp. 2298–2307, Feb. 2019 [Online]. Available: http://dx.doi.org/10.1039/c8sc04516j ↩︎
O. Obiols-Sales, A. Vishnu, N. Malaya, and A. Chandramowlishwaran, “CFDNet: a deep learning-based accelerator for fluid simulations,” arXiv [physics.flu-dyn]. 2020 [Online]. Available: http://arxiv.org/abs/2005.04485 ↩︎
J. A. Tallman, M. Osusky, N. Magina, and E. Sewall, “An Assessment of Machine Learning Techniques for Predicting Turbine Airfoil Component Temperatures, Using FEA Simulations for Training Data,” in ASME Turbo Expo 2019: Turbomachinery Technical Conference and Exposition, 2019 [Online]. Available: https://asmedigitalcollection.asme.org/GT/proceedings-abstract/GT2019/58646/V05AT20A002/1066873. [Accessed: 23-Feb-2020] ↩︎
3 - Metadata Subgroup
Metadata subgroup informatin
This subgroup is lead but University of Tennessee, Knoxville.
Schema Development
As part of the logging, reporting activities, this subgroup is tasked to create appropriate schema to follow the FAIR principles. Below is a general overview of the major hierarchy of data that needs to be recorded for reproducibility.
- Hardware specifications
- Compute: CPUs, Accelerators
- Memory: caches, NUMA
- Network: on-node CPU and accelerator coherency, NIC and off-node switches
- Peripherals
- Storage: primary (SSD), secondary (HDD), tertiary (RAID/remote)
- Firmware: ID/release date
- Software stack
- Compiler: GCC, Clang, vendor
- AI framework: TensorFlow, PyTorch, Keras, MxNet
- Tensor backend: JAX, TVM
- Runtime: JVM, OpenMP, CUDA
- Messaging API: MPI, NCCL, RCCL
- OS: Linux
- Container: Singularity, Docker, CharlieCloud
- Input data
- Data sets (version, size)
- Image: MNIST digits/fashion, CIFAR 10/100, ImageNet, VGG
- Language: Transformer
- Science: instrument, simulation
- Annotations
- Data sets (version, size)
- Model data
- Release date, ID, repo/branch/tag/hash, URL
- Output data
- Performance rate: training, inference
- Power draw: training, inference
- Energy consumption
- Convergence: epochs
- Accuracy, recall
4 - Publications
We list here the Publications of this project
The collection of publications related to this project.
- Note: Please do not edit this page as it is automatically generated. To add new refernces please edit the bibtex file
[1] G. Fox, P. Beckman, S. Jha, P. Luszczek, and V. Jadhao, “Surrogate benchmark initiative SBI: FAIR surrogate benchmarks supporting AI and simulation research,” in ASCR computer science (CS) principal investigators (PI) meeting, Atlanta, GA: U.S. Department of Energy (DOE), Office of Science (SC), Feb. 2024, p. 1. Available: https://github.com/sbi-fair/sbi-fair.github.io/raw/main/pub/doe_abstract.pdf
[2] T. Zhong, J. Zhao, X. Guo, Q. Su, and G. Fox, “RINAS: Training with dataset shuffling can be general and fast.” 2023. Available: https://arxiv.org/abs/2312.02368
[3] C. Luo, T. Zhong, and G. Fox, “RTP: Rethinking tensor parallelism with memory deduplication.” 2023. Available: https://arxiv.org/abs/2311.01635
[4] “Quadri-partite quantum-assisted VAE as a calorimeter surrogate,” in Bulletin of the american physical society, in APS march meeting. American Physical Society Sites. Available: https://meetings.aps.org/Meeting/MAR24/Session/Y50.5
[5] J. Q. Toledo-Marín, G. Fox, J. P. Sluka, and J. A. Glazier, “Deep learning approaches to surrogates for solving the diffusion equation for mechanistic real-world simulations.” 2021. Available: https://arxiv.org/abs/2102.05527
[6] J. Q. Toledo-Marín, G. Fox, J. P. Sluka, and J. A. Glazier, “Deep learning approaches to surrogates for solving the diffusion equation for mechanistic real-world simulations,” Frontiers in Physiology, vol. 12, 2021, doi: 10.3389/fphys.2021.667828.
[7] J. Kadupitiya, F. Sun, G. Fox, and V. Jadhao, “Machine learning surrogates for molecular dynamics simulations of soft materials,” Journal of Computational Science, vol. 42, p. 101107, 2020, Available: https://par.nsf.gov/servlets/purl/10188151
[8] V. Jadhao and J. Kadupitiya, “Integrating machine learning with hpc-driven simulations for enhanced student learning,” in 2020 IEEE/ACM workshop on education for high-performance computing (EduHPC), IEEE, 2020, pp. 25–34. Available: https://api.semanticscholar.org/CorpusID:221376417
[9] A. Clyde et al., “Protein-ligand docking surrogate models: A SARS-CoV-2 benchmark for deep learning accelerated virtual screening.” 2021. Available: https://arxiv.org/abs/2106.07036
[10] E. A. Huerta et al., “FAIR for AI: An interdisciplinary and international community building perspective,” Scientific Data, vol. 10, no. 1, p. 487, 2023, Available: https://doi.org/10.1038/s41597-023-02298-6
[11] G. von Laszewski, J. P. Fleischer, and G. C. Fox, “Hybrid reusable computational analytics workflow management with cloudmesh.” 2022. Available: https://arxiv.org/abs/2210.16941
[12] V. Chennamsetti et al., “MLCommons cloud masking benchmark with early stopping.” 2023. Available: https://arxiv.org/abs/2401.08636
[13] G. von Laszewski and R. Gu, “An overview of MLCommons cloud mask benchmark: Related research and data.” 2023. Available: https://arxiv.org/abs/2312.04799
[14] G. von Laszewski et al., “Whitepaper on reusable hybrid and multi-cloud analytics service framework.” 2023. Available: https://arxiv.org/abs/2310.17013
[15] G. von Laszewski, J. P. Fleischer, G. C. Fox, J. Papay, S. Jackson, and J. Thiyagalingam, “Templated hybrid reusable computational analytics workflow management with cloudmesh, applied to the deep learning MLCommons cloudmask application,” in eScience’23, Limassol, Cyprus: Second Workshop on Reproducible Workflows, Data,; Security (ReWorDS 2022), 2023. Available: https://github.com/cyberaide/paper-cloudmesh-cc-ieee-5-pages/raw/main/vonLaszewski-cloudmesh-cc.pdf
[16] G. von Laszewski et al., “Opportunities for enhancing MLCommons efforts while leveraging insights from educational MLCommons earthquake benchmarks efforts,” Frontiers in High Performance Computing, vol. 1, no. 1233877, p. 31, 2023, Available: https://doi.org/10.3389/fhpcp.2023.1233877
[17] G. von Laszewski, “Cloudmesh.” Web Page, Jan. 2024. Available: https://github.com/orgs/cloudmesh/repositories
[18] G. von Laszewski, “Reusable hybrid and multi-cloud analytics service framework,” in 4th international conference on big data, IoT, and cloud computing (ICBICC 2022), Chengdu, China: IASED, 2022. Available: www.icbicc.org
5 - Team
The team members of the project
- Geoffrey Fox, Indiana University (Principal Investigator)
- Vikram Jadhao, Indiana University (Co-Investigator)
- Gregor von Laszewski, Indiana University (Co-Investigator), laszewski@gmail.com, https://laszewski.github.io
- Rick Stevens, Argonne National Laboratory (Co-Investigator)
- Peter Beckman, Argonne National Laboratory (Co-Investigator)
- Kamil Iskra, Argonne National Laboratory (Co-Investigator)
- Min Si, Argonne National Laboratory (Co-Investigator)
- Jack Dongarra, University of Tennessee, Knoxville (Co-Investigator)
- Piotr Luszczek, University of Tennessee, Knoxville (Co-Investigator)
- Shantenu Jha, Rutgers University (Co-Investigator)
6 - Surrogates
A list of surrogates we look at
A list of surrogates
6.1 - AutoPhaseNN: unsupervised physics-aware deep learning of 3D nanoscale Bragg coherent diffraction imaging
A DL-based approach which learns to solve the phase problem in 3D X-ray Bragg coherent diffraction imaging (BCDI) without labeled data.
Metadata
Model autophasenn.json
Datasets autoPhaseNN_aicdi.json
AutoPhaseNN 1, a physics-aware unsupervised deep convolutional neural network (CNN) that learns to solve the phase problem without ever being shown real space images of the sample amplitude or phase. By incorporating the physics of the X-ray scattering into the network design and training, AutoPhaseNN learns to predict both the amplitude and phase of the sample given the measured diffraction intensity alone. Additionally, unlike previous deep learning models, AutoPhaseNN does not need the ground truth images of sample’s amplitude and phase at any point, either in training or in deployment. Once trained, the physical model is discarded and only the CNN portion is needed which has learned the data inversion from reciprocal space to real space and is ~100 times faster than the iterative phase retrieval with comparable image quality. Furthermore, we show that by using AutoPhaseNN’s prediction as the learned prior to iterative phase retrieval, we can achieve consistently higher image quality, than neural network prediction alone, at 10 times faster speed than iterative phase retrieval alone.
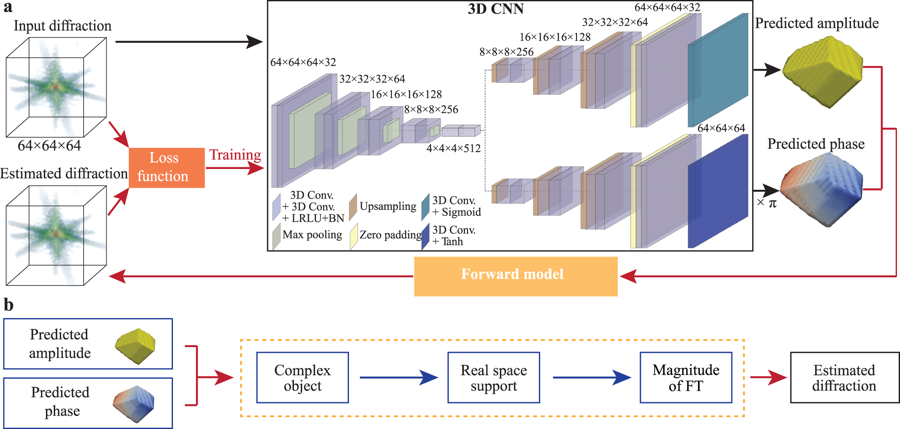
Fig. 1: Schematic of the neural network structure of AutoPhaseNN model during training.
a) The model consists of a 3D CNN and the X-ray scattering forward model. The 3D
CNN is implemented with a convolutional auto-encoder and two deconvolutional
decoders using the convolutional, maximum pooling, upsampling and zero padding
layers. The physical knowledge is enforced via the Sigmoid and Tanh activation
functions in the final layers. b The X-ray scattering forward model includes the
numerical modeling of diffraction and the image shape constraints. It takes the
amplitude and phase from the 3D CNN output to form the complex image. Then the
estimated diffraction pattern is obtained from the FT of the current estimation
of the real space image.
Image from: Yao, Y. et al / CC-BY
References
Yao, Y., Chan, H., Sankaranarayanan, S. et al. AutoPhaseNN: unsupervised physics-aware deep learning of 3D nanoscale Bragg coherent diffraction imaging. npj Comput Mater 8, 124 (2022). https://doi.org/10.1038/s41524-022-00803-w ↩︎ ↩︎
6.2 - Calorimeter surrogates
The Kaggle calorimeter challenge uses generative AI to produce a surrogate for the Monte Carlo calculation of a calorimeter response to an incident particle (ATLAS data at LHC calculated with GEANT4).
Overview
The Kaggle calorimeter challenge uses generative AI to produce a surrogate for the Monte Carlo calculation of a calorimeter response to an incident particle (ATLAS data at LHC calculated with GEANT4). Variational Auto Encoders, GANs, Normalizing Flows, and Diffusion Models. We also have a surrogate using a Quantum Computer (DWAVE) annealer to generate random samples. We have identified four different surrogates that are available openly from Kaggle and later submissions.
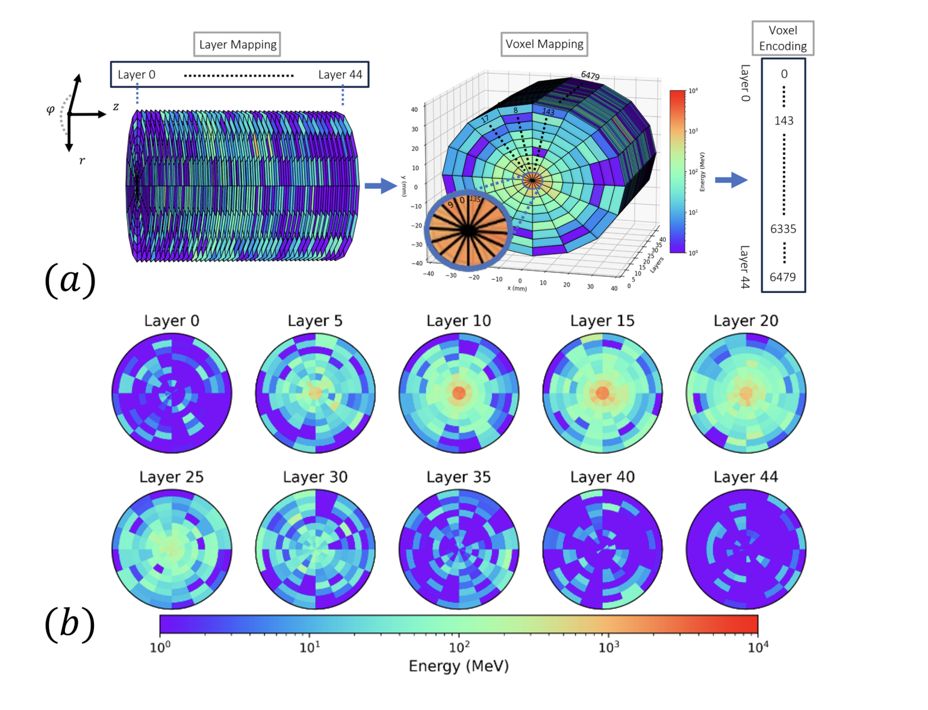
Figure 1: CaloChallenge Dataset.
Details
Accurate simulation plays a crucial role in particle physics by bridging theoretical models with experimental data to uncover the universe’s fundamental properties. At the Large Hadron Collider (LHC), simulations based on Monte Carlo methods model the interactions of billions of particles, including complex calorimeter shower events—cascades of secondary particles produced when high-energy particles hit detector materials. The widely-used Geant4 1 simulation toolkit provides highly detailed physics-based simulations, but its computational cost is extremely high, making up over 75% of the total simulation time 2. With the upcoming High-Luminosity LHC (HL-LHC) 3,4 upgrade in 2029, the collider will generate larger datasets with higher precision requirements, significantly increasing the demand for computational resources. To mitigate this, researchers are exploring generative models commonly used in image and text generation—as surrogate models that can generate realistic calorimeter showers at a fraction of the computational cost. In recent years, several approaches based on Generative Adversarial Networks(GAN) 5, 6, 7, 8, 9, 10, Diffusion 11 12, 13, 14, 15, 16, 17, 18, 19, Variational Autoencoders (VAEs) 20, 21, 22, 23, 24, 25, 26, 27, 28 and Normalizing Flows 29, 30, 31, 32, 33, 34, 35 have been proposed. However, evaluating these models remains challenging because the physical characteristics of calorimeter showers differ significantly from traditional image- and text-based data. 36, 37 conducted a rigorous evaluation of these generative models using standard datasets and a diverse set of metrics derived from physics, computer vision, and statistics. Although 36 sheds light on the existent correlations between layers, they do not quantify correlations between layers and voxels. In this work, we propose Correlation Frobenius Distance (CFD), an evaluation metric for generative models of calorimeter shower simulation. This metric measures how the consecutive layers and voxels of generated samples are correlated with each other compared to Geant4 samples. CFD helps evaluate the consistency of energy deposition patterns across layers, capturing the spatial correlations in the calorimeter shower. Lower CFD values indicate that the generated samples better preserve the correlations observed in Geant4 simulations. We compared four different models (CaloDream 19, CaloScore v2 18, CaloDiffusion 27, and CaloINN 33) on Dataset 2 38 from CaloChallenge 2022 13 for CFD, our observation reveals that CaloDream can capture correlations between consecutive layers and voxels the best. Furthermore, we explored the impact of using full versus mixed precision modes during inference for CaloDiffusion. Our observation shows that mixed precision inference does not speed up inference for Dataset 1 39 and Dataset 2 39. However, it significantly improves inference time for Dataset 3 39, without compromising performance. The Code is available in GitHub at 40.
Additional relevant references include:
Team contributed refernces include
References
Team contributed refernces are marked in bold
Agostinelli, Sea, et al. “GEANT4—a simulation toolkit.” Nuclear instruments and methods in physics research section A: Accelerators, Spectrometers, Detectors and Associated Equipment 506.3 (2003): 250-303. ↩︎
Muškinja, Miha, John Derek Chapman, and Heather Gray. “Geant4 performance optimization in the ATLAS experiment.” EPJ Web of Conferences. Vol. 245. EDP Sciences, 2020. ↩︎
“New Schedule for CERN’s Accelerators.” CERN, 5 Dec. 2023, [https://home.cern/news/news/accelerators/new-schedule-cerns-accelerators]:(https://home.cern/news/news/accelerators/new-schedule-cerns-accelerators). Accessed 28 Feb. 2025. ↩︎
“Computing at CERN.” CERN, https://home.web.cern.ch/science/computing. Accessed 28 Feb. 2025. ↩︎
ATLAS collaboration. “Fast simulation of the ATLAS calorimeter system with Generative Adversarial Networks.” ATLAS PUB Note, CERN, Geneva (2020). ↩︎
Ghosh, Aishik, and ATLAS collaboration. “Deep generative models for fast shower simulation in ATLAS.” Journal of Physics: Conference Series. Vol. 1525. No. 1. IOP Publishing, 2020. ↩︎
Giannelli, Michele Faucci, and Rui Zhang. “CaloShowerGAN, a generative adversarial network model for fast calorimeter shower simulation.” The European Physical Journal Plus 139.7 (2024): 597. ↩︎
Paganini, Michela, Luke de Oliveira, and Benjamin Nachman. “Accelerating science with generative adversarial networks: an application to 3D particle showers in multilayer calorimeters.” Physical review letters 120.4 (2018): 042003. ↩︎
de Oliveira, Luke, Michela Paganini, and Benjamin Nachman. “Learning particle physics by example: location-aware generative adversarial networks for physics synthesis.” Computing and Software for Big Science 1.1 (2017): 4. ↩︎
Paganini, Michela, Luke de Oliveira, and Benjamin Nachman. “CaloGAN: Simulating 3D high energy particle showers in multilayer electromagnetic calorimeters with generative adversarial networks.” Physical Review D 97.1 (2018): 014021. ↩︎
Acosta, Fernando Torales, et al. “Comparison of point cloud and image-based models for calorimeter fast simulation.” Journal of Instrumentation 19.05 (2024): P05003. ↩︎
Amram, Oz, and Kevin Pedro. “Denoising diffusion models with geometry adaptation for high fidelity calorimeter simulation.” Physical Review D 108.7 (2023): 072014. ↩︎
Buhmann, Erik, et al. “CaloClouds: fast geometry-independent highly-granular calorimeter simulation.” Journal of Instrumentation 18.11 (2023): P11025. ↩︎ ↩︎
Buhmann, Erik, et al. “CaloClouds II: ultra-fast geometry-independent highly-granular calorimeter simulation.” Journal of Instrumentation 19.04 (2024): P04020. ↩︎
Cresswell, Jesse C., and Taewoo Kim. “Scaling Up Diffusion and Flow-based XGBoost Models.” arXiv preprint arXiv:2408.16046 (2024). ↩︎
Madula, T., and V. M. Mikuni. “CaloLatent: Score-based Generative Modelling in the Latent Space for Calorimeter Shower Generation NeurIPS Workshop on Machine Learning and the Physical Sciences URL https://ml4physicalsciences. github. io/2023/files.” NeurIPS_ ML4PS_2023_19. pdf (2023). ↩︎
Mikuni, Vinicius, and Benjamin Nachman. “Score-based generative models for calorimeter shower simulation.” Physical Review D 106.9 (2022): 092009. ↩︎
Mikuni, Vinicius, and Benjamin Nachman. “CaloScore v2: single-shot calorimeter shower simulation with diffusion models.” Journal of Instrumentation 19.02 (2024): P02001. ↩︎ ↩︎
Favaro, Luigi, et al. “CaloDREAM–Detector Response Emulation via Attentive flow Matching.” arXiv preprint arXiv:2405.09629 (2024). ↩︎ ↩︎
Cresswell, Jesse C., et al. “CaloMan: Fast generation of calorimeter showers with density estimation on learned manifolds.” arXiv preprint arXiv:2211.15380 (2022). ↩︎
Buhmann, Erik, et al. “Decoding photons: Physics in the latent space of a BIB-AE generative network.” EPJ Web of Conferences. Vol. 251. EDP Sciences, 2021. ↩︎
Buhmann, Erik, et al. “Getting high: High fidelity simulation of high granularity calorimeters with high speed.” Computing and Software for Big Science 5.1 (2021): 13. ↩︎
Diefenbacher, Sascha, et al. “New angles on fast calorimeter shower simulation.” Machine Learning: Science and Technology 4.3 (2023): 035044. ↩︎
Salamani, Dalila, Anna Zaborowska, and Witold Pokorski. “MetaHEP: Meta learning for fast shower simulation of high energy physics experiments.” Physics Letters B 844 (2023): 138079. ↩︎
Abhishek, Abhishek, et al. “CaloDVAE: Discrete variational autoencoders for fast calorimeter shower simulation.” arXiv preprint arXiv:2210.07430 (2022). ↩︎
Caloqvae: Simulating high-energy particle calorimeter interactions using hybrid quantum-classical generative models ↩︎
Hoque, Sehmimul, et al. “CaloQVAE: Simulating high-energy particle-calorimeter interactions using hybrid quantum-classical generative models.” The European Physical Journal C 84.12 (2024): 1-7. ↩︎ ↩︎
Lu, Ian, et al. “Zephyr quantum-assisted hierarchical Calo4pQVAE for particle-calorimeter interactions.” arXiv preprint arXiv:2412.04677 (2024). ↩︎
Krause, Claudius, and David Shih. “Fast and accurate simulations of calorimeter showers with normalizing flows.” Physical Review D 107.11 (2023): 113003. ↩︎
Krause, Claudius, Ian Pang, and David Shih. “CaloFlow for CaloChallenge dataset 1.” SciPost Physics 16.5 (2024): 126. ↩︎
Buckley, Matthew R., et al. “Inductive simulation of calorimeter showers with normalizing flows.” Physical Review D 109.3 (2024): 033006. ↩︎
Diefenbacher, S., et al. “L2LFlows: generating high-fidelity 3D calorimeter images (2023).” arXiv preprint arXiv:2302.11594 18: P10017. ↩︎
Ernst, Florian, et al. “Normalizing flows for high-dimensional detector simulations.” arXiv preprint arXiv:2312.09290 (2023). ↩︎ ↩︎
Liu, Junze, et al. “Geometry-aware autoregressive models for calorimeter shower simulations.” arXiv preprint arXiv:2212.08233 (2022). ↩︎
Schnake, Simon, Dirk Krücker, and Kerstin Borras. “CaloPointFlow II generating calorimeter showers as point clouds.” arXiv preprint arXiv:2403.15782 (2024). ↩︎
Ahmad, Farzana Yasmin, Vanamala Venkataswamy, and Geoffrey Fox. “A comprehensive evaluation of generative models in calorimeter shower simulation.” arXiv preprint arXiv:2406.12898 (2024). ↩︎ ↩︎
Krause, Claudius, et al. “Calochallenge 2022: A community challenge for fast calorimeter simulation.” arXiv preprint arXiv:2410.21611 (2024). ↩︎
Ahmad, F. Y. Generated Samples of Dataset 2 from Calochallenge_2022. Zenodo, 17 Feb. 2025, doi:10.5281/zenodo.14883798. ↩︎
CaloChallenge Homepage*, calochallenge.github.io/homepage/. Accessed 3 Mar. 2025. ↩︎ ↩︎ ↩︎
GitHub: https://github.com/Aaheer17/Benchmarking_Calorimeter_Shower_Simulation_Generative_AI/tree/main ↩︎
Michele Faucci Giannelli, Gregor Kasieczka, Claudius Krause, Ben Nachman, Dalila Salamani, David Shih, Anna Zaborowska, Fast calorimeter simulation challenge 2022 - dataset 1,2 and 3 [data set]. zenodo., https://doi.org/10.5281/zenodo.8099322, https://doi.org/10.5281/zenodo.6366271, https://doi.org/10.5281/zenodo.6366324 (2022). ↩︎ ↩︎
ATLAS Collaboration, ATLAS software and computing HL-LHC roadmap, Tech. Rep. (Technical report, CERN, Geneva. http://cds.cern.ch/record/2802918, 2022). ↩︎ ↩︎ ↩︎
Conditioned quantum-assisted deep generative surrogate for particle-calorimeter interactions, J Quetzalcoatl Toledo-Marin, Sebastian Gonzalez, Hao Jia, Ian Lu, Deniz Sogutlu, Abhishek Abhishek, Colin Gay, Eric Paquet, Roger Melko, Geoffrey C Fox, Maximilian Swiatlowski, Wojciech Fedorko, 2024/10/30 arXiv preprint arXiv:2410.22870, Abstract: Particle collisions at accelerators such as the Large Hadron Collider, recorded and analyzed by experiments such as ATLAS and CMS, enable exquisite measurements of the Standard Model and searches for new phenomena. Simulations of collision events at these detectors have played a pivotal role in shaping the design of future experiments and analyzing ongoing ones. However, the quest for accuracy in Large Hadron Collider (LHC) collisions comes at an imposing computational cost, with projections estimating the need for millions of CPU-years annually during the High Luminosity LHC (HL-LHC) run 42. Simulating a single LHC event with Geant4 currently devours around 1000 CPU seconds, with simulations of the calorimeter subdetectors in particular imposing substantial computational demands 42. To address this challenge, we propose a conditioned quantum-assisted deep generative model. Our model integrates a conditioned variational autoencoder (VAE) on the exterior with a conditioned Restricted Boltzmann Machine (RBM) in the latent space, providing enhanced expressiveness compared to conventional VAEs. The RBM nodes and connections are meticulously engineered to enable the use of qubits and couplers on D-Wave’s Pegasus-structured \textit{Advantage} quantum annealer (QA) for sampling. We introduce a novel method for conditioning the quantum-assisted RBM using flux biases. We further propose a novel adaptive mapping to estimate the effective inverse temperature in quantum annealers. The effectiveness of our framework is illustrated using Dataset 2 of the CaloChallenge 41. ↩︎
Calorimeter Surrogate Research, Geoffrey Fox University of Virginia, 2024 https://docs.google.com/document/d/19g0Avj9SYbVH7qSxoVUnnFKeGMuBdD9JCHVmBQB466M/ ↩︎
Poster: https://drive.google.com/file/d/1PUiNDju_8N_wsDKI_W-g-jyCHb_5Hepo/ ↩︎
Extended abstract: Correlation Frobenius Distance: A Metric for Evaluating Generative Models in Calorimeter Shower Simulation, Farzana Yasmin Ahmada, Vanamala Venkataswamya, Geoffrey Fox, University of Virginia, https://docs.google.com/document/d/1ndHkJY41_pHYZZne58B4_7HJQKTCxPzeMWVMJ0bsnOE ↩︎
6.3 - Virtual tissue
This surrugate simulates a virtual tissue
Overview
Neural networks (NNs) have been demonstrated to be a viable alternative to traditional direct numerical evaluation algorithms, with the potential to accelerate computational time by several orders of magnitude. In the present paper we study the use of encoder-decoder convolutional neural network (CNN) algorithms as surrogates for steady-state diffusion solvers. The construction of such surrogates requires the selection of an appropriate task, network architecture, training set structure and size, loss function, and training algorithm hyperparameters. It is well known that each of these factors can have a significant impact on the performance of the resultant model. Our approach employs an encoder-decoder CNN architecture, which we posit is particularly wellsuited for this task due to its ability to effectively transform data, as opposed to merely compressing it. We systematically evaluate a range of loss functions, hyperparameters, and training set sizes. Our results indicate that increasing the size of the training set has a substantial effect on reducing performance fluctuations and overall error. Additionally, we observe that the performance of the model exhibits a logarithmic dependence on the training set size. Furthermore, we investigate the effect on model performance by using different subsets of data with varying features. Our results highlight the importance of sampling the configurational space in an optimal manner, as this can have a significant impact on the performance of the model and the required training time. In conclusion, our results suggest that training a model with a pre-determined error performance bound is not a viable approach, as it does not guarantee that edge cases with errors larger than the bound do not exist. Furthermore, as most surrogate tasks involve a high dimensional landscape, an ever increasing training set size is, in principle, needed, however it is not a practical solution.
Figure 1: Sketch of the NN architecture for virtual tissue surrogate.
References
Analyzing the Performance of Deep Encoder-Decoder Networks as Surrogates for a Diffusion Equation, J. Quetzalcoatl Toledo-Marin, James A. Glazier, Geoffrey Fox https://arxiv.org/pdf/2302.03786.pdf> ↩︎
There is an earlier surrogate referred to in this arxiv. It was published: Toledo-Marín J. Quetzalcóatl , Fox Geoffrey , Sluka James P. , Glazier James A., Deep Learning Approaches to Surrogates for Solving the Diffusion Equation for Mechanistic Real-World Simulations,Frontiers in Physiology, Vol. 12, 2021 doi: 10.3389/fphys.2021.667828, ISSNI 1664-042X, https://www.frontiersin.org/journals/physiology/articles/10.3389/fphys.2021.667828 ↩︎
6.4 - Cosmoflow
The CosmoFlow training application benchmark from the MLPerf HPC v0.5 benchmark suite. It involves training a 3D convolutional neural network on N-body cosmology simulation data to predict physical parameters of the universe.
Metadata
Model cosmoflow.json
Datasets
cosmoUniverse_2019_05_4parE_tf_v2.json
cosmoUniverse_2019_05_4parE_tf_v2_mini.json
Overview
This application is based on the original CosmoFlow paper presented at SC18 and continued by the ExaLearn project, and adopted as a benchmark in the MLPerf HPC suite. It involves training a 3D convolutional neural network on N-body cosmology simulation data to predict physical parameters of the universe. The reference implementation for MLPerf HPC v0.5 CosmoFlow uses TensorFlow with the Keras API and Horovod for data-parallel distributed training. The dataset comes from simulations run by ExaLearn, with universe volumes split into cubes of size 128x128x128 with 4 redshift bins. The total dataset volume preprocessed for MLPerf HPC v0.5 in TFRecord format is 5.1 TB. The target objective in MLPerf HPC v0.5 is to train the model to a validation mean-average-error < 0.124. However, the problem size can be scaled down and the training throughput can be used as the primary objective for a small scale or shorter timescale benchmark.123
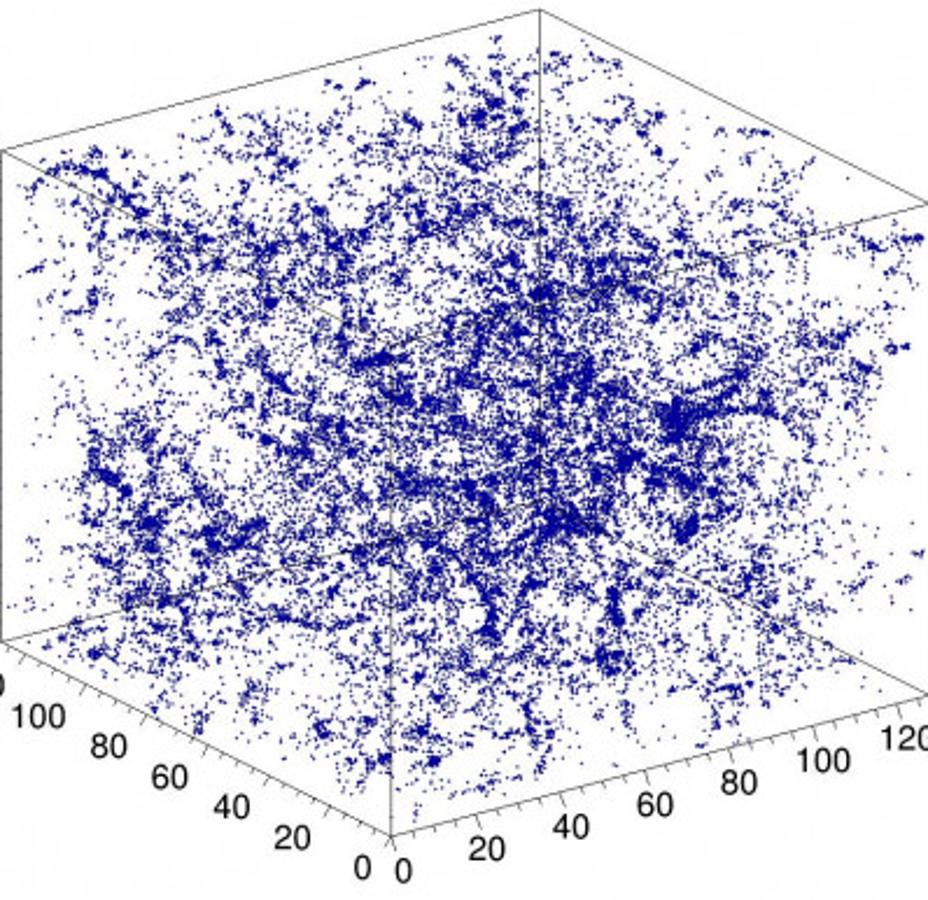
Figure 1: Example simulation of dark matter in the universe used as input to the CosmoFlow network. Copied from [NERSC](https://www.nersc.gov/news-publications/nersc-news/science-news/2018/nersc-intel-cray-harness-the-power-of-deep-learning-to-better-understand-the-universe/)
References
6.5 - Fully ionized plasma fluid model closures
The closure problem in fluid modeling is a well-known challenge to modelers aiming to accurately describe their system of interest. We will choose one of the surrogates form this application and develop a reference implementation and tutorial.
Fully ionized plasma fluid model closures (Argonne):1 The closure problem in fluid modeling is a well-known challenge to modelers aiming to accurately describe their system of interest. Analytic formulations in a wide range of regimes exist but a practical, generalized fluid closure for magnetized plasmas remains an elusive goal. There are scenarios where complex physics prevents a simple closure being assumed, and the question as to what closure to employ has a non-trivial answer. In a proof-of-concept study, Argonne researchers turned to machine learning to try to construct surrogate closure models that map the known macroscopic variables in a fluid model to the higher-order moments that must be closed. In their study, the researchers considered three closures: Braginskii, Hammett-Perkins, and Guo-Tang; for each of them, they tried three types of ANNs: locally connected, convolutional, and fully connected. Applying a physics-informed machine learning approach, they found that there is a benefit to tailoring a specific network architecture informed by the physics of the plasma regime each closure is designed for, rather than carelessly applying an unnecessarily complex general network architecture. will choose one of the surrogates and bring it up an early example for SBI with reference implementation and tutorial documentation. As a follow-up, the Argonne team will tackle more challenging problems.
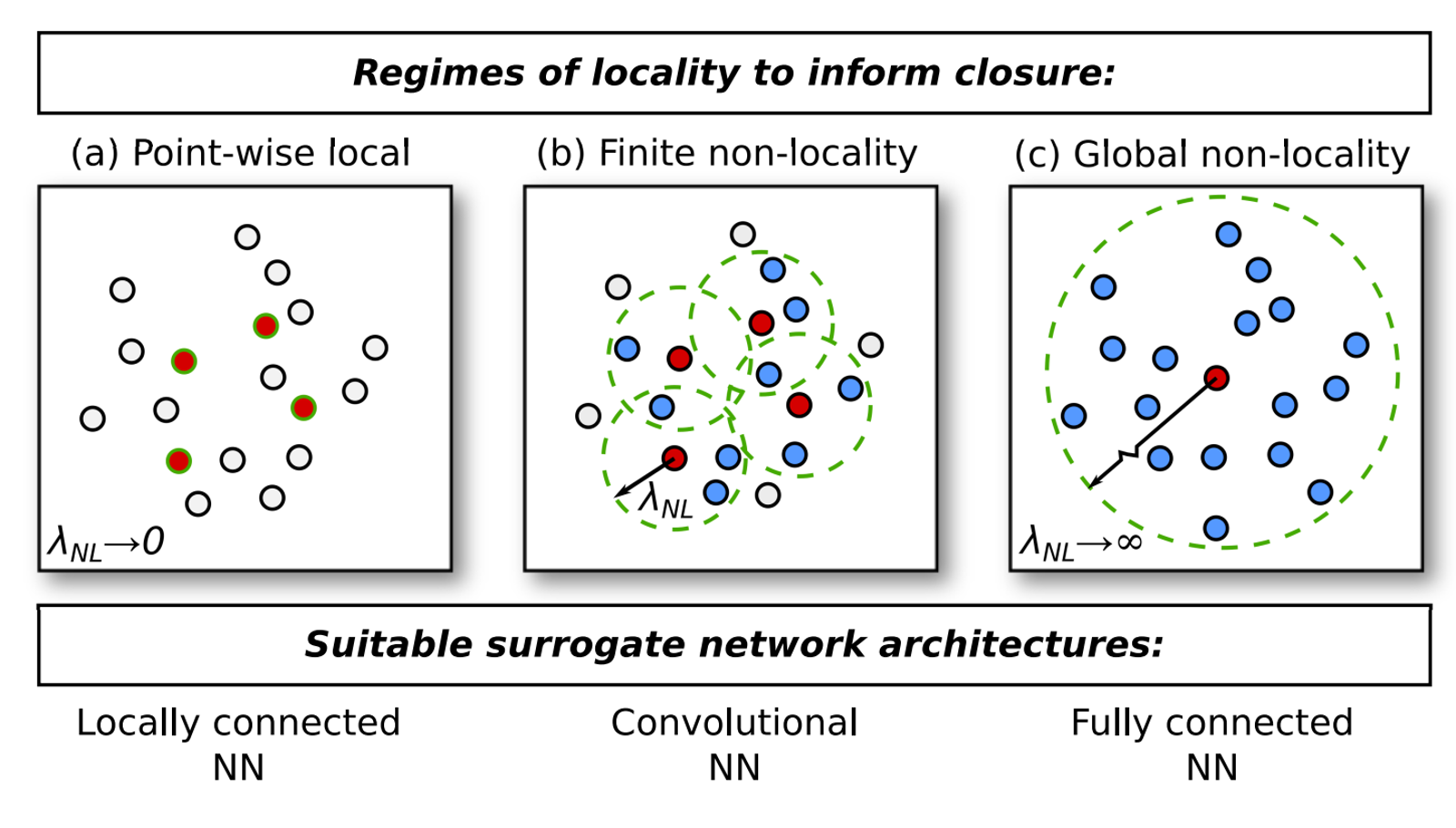
Figure 1: Simple schematic of varying classes of closure formulations.
References
R. Maulik, N. A. Garland, X.-Z. Tang, and P. Balaprakash, “Neural network representability of fully ionized plasma fluid model closures,” arXiv [physics.comp-ph], 10-Feb-2020 [Online]. Available: http://arxiv.org/abs/2002.04106 ↩︎
6.6 - Ions in nanoconfinement
This application studies ionic structure in electrolyte solutions in nanochannels with planar uncharged surfaces and can use multiple molecular dynamics (MD) codes including LAMMPS which run on HPC supercomputers with OpenMP and MPI parallelization.
Metadata
Model nanoconfinement.json
Datasets nanoconfinement.json
This application 1 2 3 studies ionic structure in electrolyte solutions in nanochannels with planar uncharged surfaces and can use multiple molecular dynamics (MD) codes including LAMMPS 4 which run on HPC supercomputers with OpenMP and MPI parallelization.
A dense neural-net (NN) was used to learn 150 final state characteristics based on the input of 5 parameters with typical results shown in fig. 2(b) with the NN results for three important densities tracking well the MD simulation results for a wide range of unseen input system parameters. Fig. 3(a,b) shows two typical density profiles with again the NN prediction tracking well the simulation. Input quantities were confinement length, positive ion valency, negative ion valency, salt concentration, and ion diameter. Figure 2(a) shows the runtime architecture for dynamic use and update of the NN and our middleware discussed in Sec. 3.2.6 will generalize this. The inference time for this on a single core is 104 times faster than the parallel code which is itself 100 times the sequential code. This surrogate approach is the first-of-its-kind in the area of simulating charged soft-matter systems and there are many other published papers in both biomolecular and material science presenting similar successful surrogates 5 with a NN architecture similar to fig. 3(c).
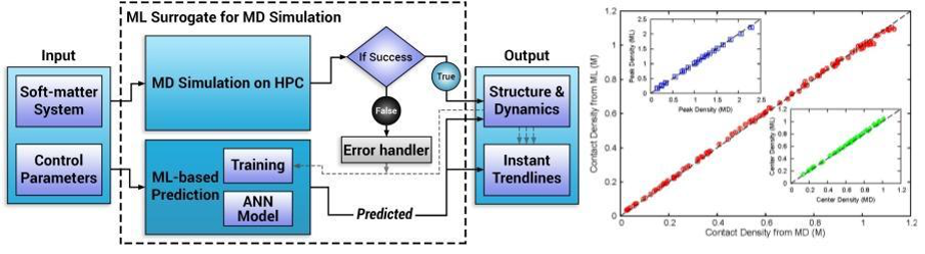
Fig. 2 a) Architecture of dynamic training of ML surrogate and b) Comparison of three final state densities (peak, contact, and center) between MD simulations and NN surrogate predictions [^5] [^51].
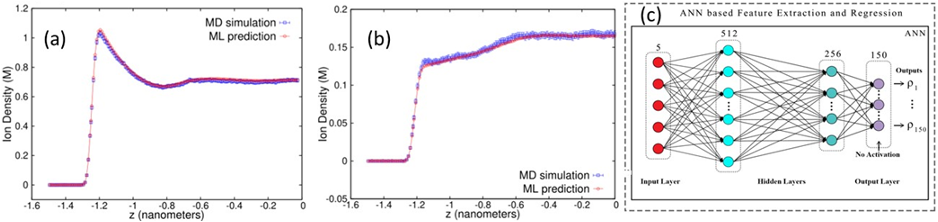
Fig. 3 (a,b) Two density profiles of confined ions for very different input parameters and comparing MD and NN. (c) Fully connected deep learning network used to learn the final densities. ReLU activation units are in the 512 and 256 node hidden layers. The output values were learned on 150 nodes.
References
JCS Kadupitiya , Geoffrey C. Fox , and Vikram Jadhao, “Machine learning for performance enhancement of molecular dynamics simulations,” in International Conference on Computational Science ICCS2019, Faro, Algarve, Portugal, 2019 [Online]. Available: http://dsc.soic.indiana.edu/publications/ICCS8.pdf ↩︎
J. C. S. Kadupitiya, F. Sun, G. Fox, and V. Jadhao, “Machine learning surrogates for molecular dynamics simulations of soft materials,” J. Comput. Sci., vol. 42, p. 101107, Apr. 2020 [Online]. Available: http://www.sciencedirect.com/science/article/pii/S1877750319310609 ↩︎
“Molecular Dynamics for Nanoconfinement.” [Online]. Available: https://github.com/softmaterialslab/nanoconfinement-md. [Accessed: 11-May-2020] ↩︎
S. Plimpton, “Fast Parallel Algorithms for Short Range Molecular Dynamics,” J. Comput. Phys., vol. 117, pp. 1–19, 1995 [Online]. Available: http://faculty.chas.uni.edu/~rothm/Modeling/Parallel/Plimpton.pdf ↩︎
Geoffrey Fox, Shantenu Jha, “Learning Everywhere: A Taxonomy for the Integration of Machine Learning and Simulations,” in IEEE eScience 2019 Conference, San Diego, California [Online]. Available: https://arxiv.org/abs/1909.13340 ↩︎
6.7 - miniWeatherML
A simplified weather model simulating flows such as supercells that are realistic enough to be challenging and simple enough for rapid prototyping in creating and learning about surrogates.
Metadata
Model miniWeatherML.json
Datasets miniWeatherML.json
Overview
MiniWeatherML is a playground for learning and developing Machine Learning (ML) surrogate models and workflows. It is based on a simplified weather model simulating flows such as supercells that are realistic enough to be challenging and simple enough for rapid prototyping in:
- Data generation and curation
- Machine Learning model training
- ML model deployment and analysis
- End-to-end workflows

Figure 1: CANcer Distributed Learning Environment
References
6.8 - OSMI
We explore the relationship between certain network configurations and the performance of distributed Machine Learning systems. We build upon the Open Surrogate Model Inference (OSMI) Benchmark, a distributed inference benchmark for analyzing the performance of machine-learned surrogate models
Overview
We explore the relationship between certain network configurations and the performance of distributed Machine Learning systems. We build upon the Open Surrogate Model Inference (OSMI) Benchmark, a distributed inference benchmark for analyzing the performance of machine-learned surrogate models developed by Wes Brewer et. Al. We focus on analyzing distributed machine-learning systems, via machine-learned surrogate models, across varied hardware environments. By deploying the OSMI Benchmark on platforms like Rivanna HPC, WSL, and Ubuntu, we offer a comprehensive study of system performance under different configurations. The paper presents insights into optimizing distributed machine learning systems, enhancing their scalability and efficiency. We also develope a framework for automating the OSMI benchmark.
Introdcution
With the proliferation of machine learning as a tool for science, the need for efficient and scalable systems is paramount. This paper explores the Open Surrogate Model Inference (OSMI) Benchmark, a tool for testing the performance of machine-learning systems via machine-learned surrogate models. The OSMI Benchmark, originally created by Wes Brewer and colleagues, serves to evaluate various configurations and their impact on system performance.
Our research pivots around the deployment and analysis of the OSMI Benchmark across various hardware platforms, including the high-performance computing (HPC) system Rivanna, Windows Subsystem for Linux (WSL), and Ubuntu environments.
In each experiment, there are a variable number of TensorFlow model server instances, overseen by a HAProxy load balancer that distributes inference requests among the servers. Each server instance operates on a dedicated GPU, choosing between the V100 or A100 GPUs available on Rivanna. This setup mirrors real-world scenarios where load balancing is crucial for system efficiency.
On the client side, we initiate a variable number of concurrent clients executing the OSMI benchmark to simulate different levels of system load and analyze the corresponding inference throughput.
On top of the original OSMI-Bench, we implemented an object-oriented interface in Python for running experiments with ease, streamlining the process of benchmarking and analysis. The experiments rely on custom-built images based on NVIDIA’s tensorflow image. The code works on several hardwares, assuming the proper images are built.
Additionally, We develop a script for launching simultaneous experiments with permutations of pre-defined parameters with Cloudmesh Experiment-Executor. The Experiment Executor is a tool that automates the generation and execution of experiment variations with different parameters. This automation is crucial for conducting tests across a spectrum of scenarios.
Finally, we analyze the inference throughput and total time for each experiment. By graphing and examining these results, we draw critical insights into the performance dynamics of distributed machine learning systems.
In summary, a comprehensive examination of the OSMI Benchmark in diverse distributed ML systems is provided. We aim to contribute to the optimization of these systems, by providing a framework for finding the best performant system configuration for a given use case. Our findings pave the way for more efficient and scalable distributed computing environments.
The architectural view of the benchmarks are depictued in Figure 1 and Figure 2.
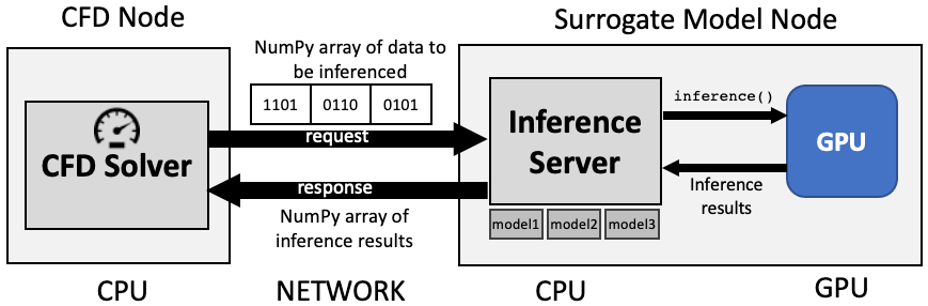
Figure 1: Surrogate calculations via a Inference Server.
Figure 2: Possible benchmark configurations to measure sped of parallel iference.
References
Brewer, Wesley, Daniel Martinez, Mathew Boyer, Dylan Jude, Andy Wissink, Ben Parsons, Junqi Yin, and Valentine Anantharaj. “Production Deployment of Machine-Learned Rotorcraft Surrogate Models on HPC.” In 2021 IEEE/ACM Workshop on Machine Learning in High Performance Computing Environments (MLHPC), pp. 21-32. IEEE, 2021, https://ieeexplore.ieee.org/abstract/document/9652868, Note that OSMI-Bench differs from SMI-Bench described in the paper only in that the models that are used in OSMI are trained on synthetic data, whereas the models in SMI were trained using data from proprietary CFD simulations. Also, the OSMI medium and large models are very similar architectures as the SMI medium and large models, but not identical. ↩︎
Brewer, Wesley, Greg Behm, Alan Scheinine, Ben Parsons, Wesley Emeneker, and Robert P. Trevino. “iBench: a distributed inference simulation and benchmark suite.” In 2020 IEEE High Performance Extreme Computing Conference (HPEC), pp. 1-6. IEEE, 2020. ↩︎
Brewer, Wesley, Greg Behm, Alan Scheinine, Ben Parsons, Wesley Emeneker, and Robert P. Trevino. “Inference benchmarking on HPC systems.” In 2020 IEEE High Performance Extreme Computing Conference (HPEC), pp. 1-9. IEEE, 2020. ↩︎
Brewer, Wesley, Chris Geyer, Dardo Kleiner, and Connor Horne. “Streaming Detection and Classification Performance of a POWER9 Edge Supercomputer.” In 2021 IEEE High Performance Extreme Computing Conference (HPEC), pp. 1-7. IEEE, 2021. ↩︎
Gregor von Laszewski, J. P. Fleischer, and Geoffrey C. Fox. 2022. Hybrid Reusable Computational Analytics Workflow Management with Cloudmesh. https://doi.org/10.48550/ARXIV.2210.16941 ↩︎
6.9 - Particle dynamics
Recurrent Neural Nets as a Particle Dynamics Integrator
Recurrent Neural Nets as a Particle Dynamics Integrator
The second IU initial application shows a rather different type of surrogate and illustrates an SBI goal to collect benchmarks covering a range of surrogate designs. Molecular dynamics simulations rely on numerical integrators such as Verlet to solve Newton’s equations of motion. Using a sufficiently small time step to avoid discretization errors, Verlet integrators generate a trajectory of particle positions as solutions to the equations of motions. In 1, 2, 3, the IU team introduces an integrator based on recurrent neural networks that is trained on trajectories generated using the Verlet integrator and learns to propagate the dynamics of particles with timestep up to 4000 times larger compared to the Verlet timestep. As shown in Fig. 4 (right) the error does not increase as one evolves the system for the surrogate while standard Verlet integration in Fig. 4 (left) has unacceptable errors even for time steps of just 10 times that used in an accurate simulation. The surrogate demonstrates a significant net speedup over Verlet of up to 32000 for few-particle (1 - 16) 3D systems and over a variety of force fields including the Lennard-Jones (LJ) potential. This application uses a recurrent plus dense neural network architecture and illustrates an important approach to learning evolution operators which can be applied across a variety of fields including Earthquake science (IU work in progress) and Fusion 4.
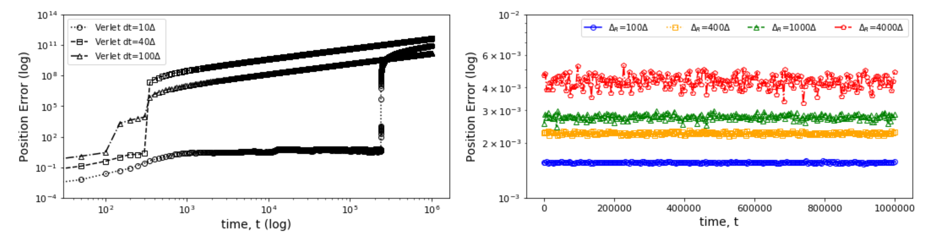
Fig. 4: Average error in position updates for 16 particles interacting with an LJ potential, The left figure is standard MD with error increasing for ∆t as 10, 40, or 100 times robust choice (0.001). On the right is the LSTM network with modest error up to t = 106 even for ∆t = 4000 times the robust MD choice.
References
JCS Kadupitiya, Geoffrey C. Fox, Vikram Jadhao, “GitHub repository for Simulating Molecular Dynamics with Large Timesteps using Recurrent Neural Networks.” [Online]. Available: https://github.com/softmaterialslab/RNN-MD. [Accessed: 01-May-2020] ↩︎
J. C. S. Kadupitiya, G. C. Fox, and V. Jadhao, “Simulating Molecular Dynamics with Large Timesteps using Recurrent Neural Networks,” arXiv [physics.comp-ph], 12-Apr-2020 [Online]. Available: http://arxiv.org/abs/2004.06493 ↩︎
J. C. S. Kadupitiya, G. Fox, and V. Jadhao, “Recurrent Neural Networks Based Integrators for Molecular Dynamics Simulations,” in APS March Meeting 2020, 2020 [Online]. Available: http://meetings.aps.org/Meeting/MAR20/Session/L45.2. [Accessed: 23-Feb-2020] ↩︎
J. Kates-Harbeck, A. Svyatkovskiy, and W. Tang, “Predicting disruptive instabilities in controlled fusion plasmas through deep learning,” Nature, vol. 568, no. 7753, pp. 526–531, Apr. 2019 [Online]. Available: https://doi.org/10.1038/s41586-019-1116-4 ↩︎
6.10 - PtychoNN: deep learning network for ptychographic imaging that predicts sample amplitude and phase from diffraction data.
A DL-based approach to solve the ptychography data inversion problem that learns a direct mapping from the reciprocal space data to the sample amplitude and phase.
Metadata
Model ptychonn.json
Datasets ptychonn_20191008_39.json
PtychoNN, uses a deep convolutional neural network to predict realspace structure and phase from far-field diffraction data. It recovers high fidelity amplitude and phase contrast images of a real sample hundreds of times faster than current ptychography reconstruction packages and reduces sampling requirements 1
References
Mathew J. Cherukara, Tao Zhou, Youssef Nashed, Pablo Enfedaque, Alex Hexemer, Ross J. Harder, Martin V. Holt; AI-enabled high-resolution scanning coherent diffraction imaging. Appl. Phys. Lett. 27 July 2020; 117 (4): 044103. https://doi.org/10.1063/5.0013065 ↩︎
7 - Software
Some software that we developed
A list of software we use to make things easiers
7.1 - cloudmesh
cloudmesh is a flexible framework to develop cloud and HPC programs using python. It is based on a number of plugins.
Overview
Cloudmesh allows the creation of an extensible commandline and commandshell tool based internally on a number of python APIs that can be loaded conveniently through plugins.
Plugins useful for this effort include
- cloudmesh-vpn1 – a convenient way to configure VPN
- cloudmesh-common2 – useful common libraries including a StopWatch for benchmarking
- cloudmesh-cmd53 – a plugin manager that allows plugins to be integrated as commandline tool or command shell
- cloudmesh-ee4 – A pluging to create AI grid searchs using LSF and SLURM jobs
- cloudmesh-cc5 – A plugin to allow benchmarks to be run in coordination on heterogeneous compute resources and multiple clusters
- cloudmesh-apptainer6 – mangae apptainers via a Python API
Cloudmesh has over 100 plugins coordinated at http://github.com/cloudmesh
References
Gregor von Laszewski, J. P. Fleischer, and Geoffrey C. Fox. 2022. Hybrid Reusable Computational Analytics Workflow Management with Cloudmesh. https://doi.org/10.48550/ARXIV.2210.16941 ↩︎
7.2 - sabath
SABATH provides benchmarking infrastructure for evaluating scientific ML/AI models. It contains support for scientific machine learning surrogates from external repositories such as SciML-Bench.
Introduction
SABATH provides benchmarking infrastructure for evaluating scientific ML/AI models. It contains support for scientific machine learning surrogates from external repositories such as SciML-Bench.
The software dependences are explicitly exposed in the surrogate model definition, which allows the use of advanced optimization, communication, and hardware features. For example, distributed, multi-GPU training may be enabled with Horovod. Surrogate models may be implemented using TensorFlow, PyTorch, or MXNET frameworks.
Models
Models are collected so far at
References
8 - Meeting Notes
Meeting Notes
8.1 - Poster
The SBI FAIR Poster.
We are happy to announce a poster about the SBI FAIR project.

Poster
https://sbi-fair.github.io/docs/notes/poster/sbi-fair-poster-finalv2.pdf
8.2 - Links
Links
Overall Project Links
- Google-group: https://groups.google.com/g/sbi-fair
- Website: https://sbi-fair.github.io/
- Publications: https://sbi-fair.github.io/docs/publications/
- The directory from proposal writing: DOE_FAIR2020-Surrogates
- Directory for this proposal: Afteraward
- Meeting Summaries Report:: https://docs.google.com/document/d/1cqMOkV9Cag6EB6HI6fR20gwhVwUeG5yijtJ3aEW0Crs
8.3 - Meeting Notes 02-05-2024
Meeting Notes from 02-05-2024
Notes
Virginia
Virginia started a list of surrogates that would help prepare any poster necessary https://docs.google.com/presentation/d/1LonfbydMlQyLBv5vh8tjATv9BxdN7GmjuU8RFyuK5aw/edit#slide=id.g2acfd0f37ff_1_151
Virginia status is https://docs.google.com/presentation/d/1LonfbydMlQyLBv5vh8tjATv9BxdN7GmjuU8RFyuK5aw/edit#slide=id.g2acfd0f37ff_1_100 and other slides here plus https://docs.google.com/presentation/d/1fqKphJlK4Q_zE1wIAxHs73c4LHFjAKzjXIiMSS_opnw/edit?usp=sharing
Web page https://sbi-fair.github.io/
Rutgers
ASCR-PI-Meeting-Feb-2024-Rutgers
Indiana
- Indiana has 2 surrogates.
- Ions in nano confinement.This code allows users to simulate ions confined between material surfaces that are nanometers apart, and extract the associated ionic structure.
time evolution: GitHub: Code for our paper “Simulating Molecular Dynamics with Large Timesteps using Recurrent Neural Networks”
See powerpoint sbi_Jadhao_2024.pptx
ANL
UTK
Other
Last Joint Presentation SBI DOE Presentation November 28 2022.pptx
The poster is FoxG_FAIR Surrogate Benchmarks .pptx or Abstract 250 words
Replacing traditional HPC computations with deep learning surrogates can dramatically improve the performance of simulations. We need to build repositories for AI models, datasets, and results that are easily used with FAIR metadata. These must cover a broad spectrum of use cases and system issues. The need for heterogeneous architectures means new software and performance issues. Further surrogate performance models are needed. The SBI (Surrogate Benchmark Initiative) collaboration between Argonne National Lab, Indiana University, Rutgers, University of Tennessee, and Virginia (lead) with MLCommons addresses these issues. The collaboration accumulates existing and generates new surrogates and hosts them (a total of around 20) in repositories. Selected surrogates become MLCommons benchmarks. The surrogates are managed by a FAIR metadata system, SABATH, developed by Tennessee and implemented for our repositories by Virginia.
The surrogate domains are Bragg coherent diffraction imaging, ptychographic imaging, Fully ionized plasma fluid model closures, molecular dynamics(2),
turbulence in computational fluid dynamics, cosmology, Kaggle calorimeter challenge(4), virtual tissue simulations(2), and performance tuning. Rutgers built a taxonomy using previous work and protein-ligand docking, which will be quantified using six mini-apps representing the system structure for different surrogate uses. Argonne has studied the data-loading and I/O structure for deep learning using inter-epoch and intra-batch reordering to improve data reuse. Their system addresses communication with the aggregation of small messages. They also study second-order optimizers using compression balancing accuracy and compression level. Virginia has used I/O parallelization to further improve performance. Indiana looked at ways of reducing the needed training set size for a given surrogate accuracy.
[1] Web Page for Surrogate Benchmark Initiative SBI: FAIR Surrogate Benchmarks Supporting AI and Simulation Research. Web Page, January 2024. URL: https://sbi-fair.github.io/. [2] E. A. Huerta, Ben Blaiszik, L. Catherine Brinson, Kristofer E. Bouchard, Daniel Diaz, Cate- rina Doglioni, Javier M. Duarte, Murali Emani, Ian Foster, Geoffrey Fox, Philip Harris, Lukas Heinrich, Shantenu Jha, Daniel S. Katz, Volodymyr Kindratenko, Christine R. Kirk- patrick, Kati Lassila-Perini, Ravi K. Madduri, Mark S. Neubauer, Fotis E. Psomopoulos, Avik Roy, Oliver R ̈ubel, Zhizhen Zhao, and Ruike Zhu. Fair for ai: An interdisciplinary and international community building perspective. Scientific Data, 10(1):487, 2023. URL: https://doi.org/10.1038/s41597-023-02298-6. Note: More references can be found on the Web site
Latex version https://www.overleaf.com/project/65b7e7262188975739dae845 with PDF FoxG_FAIR Surrogate Benchmarks _abstract.pdf https://drive.google.com/file/d/1ytrrii09tKKS2AAVuUTKGw8tmM2Xf8-N/view?usp=drive_link
Topics
Fitting of hardware and software to surrogates Uncertainty Quantification of the surrogate estimates Minimize Training Data Size needed to get reliable surrogates for a given accuracy choice. Develop and test surrogate Performance Models Findable, Accessible, Interoperable, and Reusable FAIR data ecosystem for HPC surrogates SBI collaborates with Industry and a leading machine learning benchmarking activity – MLPerf/MLCommons
Rutgers 2 slides Detailed example: AI-accelerated Protein-Ligand Docking Taxonomy and 6 mini-apps
Tennessee 6 slides SABATH structure and UTK use Cosmoflow in detail
Argonne 7 slides 5 slides High-Performance Data Loading Framework for Distributed DNN Training with Maximize data reuse: Inter-Epoch Reordering (InterER) has minimal impact on the accuracy. Intra-Batch Reordering (IntraBR) that has no impact on the accuracy. I/O balancing A strategy that aggregates small reads into a chunk read.
2 slides Scalable Communication Framework for Second-Order Optimizers using compression balancing accuracy and compression amount
Indiana Goal 1: Develop surrogates for nanoscale molecular dynamics (MD) simulations Surrogate for MD simulations of confined electrolyte ions Surrogate for time evolution operators in MD simulations
Goal 2: Investigate surrogate accuracy dependence on training dataset size
Virginia Work on I/O and Communicaion optimization Done Two Argonne one IU and one MLCommons
To do Onr argonne Fully ionized plasma fluid model closures Calorimeter Challenge: 3 (NF:CaloFlow, Diffusion:CaloDiffusion, CaloScore v2, VAEQVAE Last IU UTK Cosmoflow Performance Virtual Tissue (2) 6 Rutgers
8.4 - Meeting Notes 01-08-2024
Meeting Notes from 01-08-2024
Present: Geoffrey Fox, Gregor von Laszewski, Przemek Porebski, Piotr Luszczek, Shantenu Jha
Apologies Vikram Jadhao
- Shantenu described the background to the PI meeting for ASCR in February that was modeled on successful SCIDAC-wide meetings. It is not clear if sessions will be plenary or organized around Program manager portfolios.
- Virginia started a list of surrogates that would help prepare any poster necessary
- https://docs.google.com/presentation/d/1LonfbydMlQyLBv5vh8tjATv9BxdN7GmjuU8RFyuK5aw/edit#slide=id.g2acfd0f37ff_1_151
- Argonne would add work on I/O, compression, and second-order methods.
- Rutgers has surrogates to list, plus work on effective performance and their taxonomy of surrogate types.
- Indiana was not available due to travel, but has work on data dependence and surrogates for sustainability (a new paper).
- Tennessee has two surrogates, MiniWeatherML and Performance. Also has SABATH
- We did not set a next meeting until the PI meeting was clearer.
- Later email from DOE set the poster deadline as January 29.
8.5 - Meeting Notes 10-30-2023
Meeting Notes from 10-30-2023
Minutes of SBI-FAIR October 30 2023, Meeting
Present: Geoffrey Fox, Gregor von Laszewski, Przemek Porebski, Piotr Luszczek, Vikram Jadhao,** **Shantenu Jha, Margaret Lentz
- AI for Science report AI for Science, Energy, and Security Report | Argonne National Laboratory
- ASCAC Advanced Scientific Comput… | U.S. DOE Office of Science(SC)
- Hal Finkel’s (Director Research ASCR Advanced Scientific Computing talk ASCR Research Priorities is important
- Anticipated Solicitations in FY 2024
- Compared to FY 2023, expect a smaller number of larger, more-broadly-scoped solicitations driving innovation across ASCR’s research community.
- In appropriate areas, ASCR will expand its strategy of solicitating longer-term projects and, in most areas, encouraging partnerships between DOE National Laboratories, academic institutions, and industry.
- ASCR will continue to seek opportunities to expand the set of institutions represented in our portfolio and encourages our entire community to assist in this process by actively exploring potential collaborations with a diverse set of potential partners.
- Areas of interest include, but are not limited to:
- Applied mathematics and computer science targeting quantum computing across the full software stack.
- Applied mathematics and computer science focused on key topics in AI for Science, including scientific foundation models, decision support for complex systems, privacy-preserving federated AI systems, AI for digital twins, and AI for scientific programming.
- Microelectronics co-design combining innovation in materials, devices, systems, architectures, algorithms, and software (including through Microelectronics Research Centers).
- Correctness for scientific computing, data reduction, new visualization and collaboration paradigms, parallel discrete-event simulation, neuromorphic computing, and advanced wireless for science.
- Continued evolution of the scientific software ecosystem enabling community participation in exascale innovation, adoption of AI techniques, and accelerated research productivity.
- She noted the Executive order today, Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence | The White House, and this message (trustworthiness) will be reflected in DOE programs.
- Microelectronics will be a thrust
- NAIRR $140M is important
Rutgers
Shantenu Jha gave a thorough presentation
There were four items below with status given in **bold**
- Develop and Characterize Surrogates in the Context of NVBL Pipeline
- Published in Scientific Reports: Performance of Surrogate models without loss of accuracy (Stage 1 of NVBL Drug discovery pipeline) (Done)
- Performance & taxonomy of surrogates coupled to HPC (paper in a month) 2. Survey surrogates coupled to HPC simulations (Almost complete 2023-Q3) 3. Generalized framework of surrogate performance (Ongoing 2023-Q4) 1. Optimal Decision making in the DD pipeline (published)
- Tools (Ongoing) 4. Preliminary work on mini-apps under review; extend to FAIR mini-apps for surrogates taxonomy 5. Deployed on DOE leadership class machines
- Interact with MLCommons** (Anticipate start in 2023/Q4)**
6. Benchmarks for surrogate coupled to HPC workflows
Indiana
- Vikram Jadhao presented
- Accuracy speed up tradeoff for molecular dynamics surrogates
- Looking for datasets with errors
- Followed up with later discussions with Rutgers so can feed into software
Tennessee
- Piotr Luszczek gave presentation
- He reported on progress with SAbath and MiniWeatherML
- He is giving several presentations
Virginia
- **Presentation **
- We discussed progress with surrogates and enhancements to Sabath
- We discussed repository and noted that different models need different specific environments
- Requirements.txt will specify this
- Different target hardware needs to be supported
- OSMIBench will be released before end of year
- Support separate repositories in the future
- We discussed papers and, in particular, a poster at the Oak Ridge OLCF users meeting.
Argonne
- Finished the contract but will, of course, complete their papers.
8.6 - Meeting Notes 09-25-2023
Meeting Notes from 09-25-2023
Minutes of SBI-FAIR September 25 2023, Meeting
Present: Geoffrey Fox, Gregor von Laszewski, Przemek Porebski, Piotr Luszczek, Vikram Jadhao
Apologies: Shantenu Jha, Kamil Iskra, Margaret Lentz
Virginia
- **Presentation **
- Repository
- Specific environments are needed for different models
- Requirements.txt
- Different hardware support
- Copy MLCommons approach
- MLCube as a target
- Tools to generate targets
- Release before supercomputing
- Add MLCommons benchmarks
- Separate repositories in version 2
Argonne
- Finished the contract but will, of course, complete their papers.
Tennessee
- Piotr presented
- SABATH updates
- IBM-NASA Foundation model has multi-part datasets
- Cloudmesh uses SABATH
- Smokey Mountain presentation tomorrow
Rutgers
- See end of
- The first mini-app is ready
Indiana
- Will update the nanoconfinement app and Nanohub version still used
- Second surrogate being worked on
- Soft label work continuing
- Interested in AI for Instruments
- Surrogates help Sustainability as save energy
8.7 - Meeting Notes 08-25-2023
Meeting Notes from 08-25-2023
Minutes of SBI-FAIR August 28 2023, Meeting
- Monday, September 25, 2023, https://virginia.zoom.us/my/gc.fox
Present: Geoffrey Fox, Gregor von Laszewski, Przemek Porebski, Kamil Iskra,, Baixi Sun. Piotr Luszczek,
Apologies: Shantenu Jha, Vikram Jadhao, Margaret Lentz (Rutgers and Indiana not presented)
Virginia
- SABATH extensions
- OSMIBench improved
- Experiment Executor added in Cloudmesh
- Argonne surrogates supported
Argonne
- Baixi presented their new work
- SOLAR paper with artifacts submitted
- The communication bottleneck in the second order method K-FAC addressed with compression and sparsification methods with SSO Framework
Tennessee
- Piotr described Virginia’s enhancements
- IBM-NASA multi-part datasets in Foundation model
- Smokey Mountain Conference
- Integration with MLCommons Croissant using Schema.org
8.8 - Meeting Notes 07-31-2023
Meeting Notes from 07-31-2023
Minutes of SBI-FAIR July 31 2023, Meeting
- Monday, August 28, 2023, https://virginia.zoom.us/my/gc.fox
- Monday, September 25, 2023, https://virginia.zoom.us/my/gc.fox
Present: Geoffrey Fox, Gregor von Laszewski, Przemek Porebski, Kamil Iskra, Xiaodong Yu, Baixi Sun. Piotr Luszczek, Shantenu Jha
Apologies: Vikram Jadhao,
Virginia
- Geoffrey presented the Virginia Update https://docs.google.com/presentation/d/132erkV49Lgd0ZFx-AtNWJPRwTrxc480m-rU6jmvMmYA/edit?usp=sharing, which also included Indiana (see below)
- Good progress with Argonne Surrogates
- We have added PtychoNN to SABATH, and we have run AutoPhaseNN on Rivanna
- We reviewed other surrogates from Virginia including OSMIBench and a new Calorimeter simulation
- We are working well with Tennessee on SABATH
- Gregor finished with a little study on use of Rivanna – the Virginia Supercomputer
Indiana
- Vikram is still traveling in India and was not able to join today’s meeting. He shared by email the following updates.These are included in Virginia Presentation
- the nanoconfinement surrogate repository is updated with the latest results from the sample size study published in JCTC, Probing Accuracy-Speedup Tradeoff in Machine Learning Surrogates for Molecular Dynamics Simulations | Journal of Chemical Theory and Computation
- https://github.com/softmaterialslab/nanoconfinement-md/tree/master/python/surrogate_samplesize
- Coordinate with Fanbo Sun who is leading the development of this surrogate and conducted the sample size study that I have shared in our meetings.
- Working on preparing the dataset for the follow-up study to JCTC
- literature review: if folks are interested, the special issue on machine learning for molecular simulation in JCTC has many interesting papers (including surrogates): Journal of Chemical Theory and Computation | Vol 19, No 14
Argonne
- Argonne’s funds have essentially finished
- Xiaodong Yu is moving to Stevens
- New compression study comparing methods that are error bounded or nott – their performance differs by a factor of 4-6
- Baixi gave an update presentation SSO: A Highly Scalable Second-order Optimization Framework ffor Deep Neural Networks via Communication Reduction
- Quantized Stochastic Gradient Descent QSGD Non error bounded
- Model accuracy versus compression tradeoff
- Unable to utilize error-feedback due to GPU memory being filled by large models and large batch size.
- Looked at different rounding methods
- Stochastic rounding preserves direction better as not so many zeros
- Revised our I/O paper i.e., SOLAR based on the reviews, submitting to ppopp’24 with new experiments and better writeup
Rutgers
- The surrogate survey paper is making good progress with DeepDriveMD other motifs.
- Andre Merzy is working on associated Miniapps (surrogates)
- Will work with MLCommons in October
Tennessee
- Piotr presented his groups work https://drive.google.com/file/d/1ep9zxdv25I3MJmPt5YcJi32SHu5BAF4J/view?usp=sharing
- MiniWeatherML running with MPI and with or without CUDA.
- No external dataset is required
- SABATH making good progress in collaboration with Virginia
- They are working on Cosmoflow
- Piotr noted that those sites that are continuing with the project will need to submit a project report very soon. Geoffrey shared his project report to allow a common story
8.9 - Meeting Notes 06-26-2023
Meeting Notes from 06-26-2023
Minutes of SBI-FAIR June 26, 2023, Meeting
**Present: **Geoffrey Fox, Gregor von Laszewski, Przemek Porebski, Kamil Iskra, Xiaodong Yu, Baixi Sun. Vikram Jadhao, Piotr Luszczek, Shantenu Jha, Margaret Lentz
Virginia
- This was presented by Geoffrey
- He described work on new surrogates, including LHC Calorimeter, Epidemiology, Extended virtual tissue, and Earthquake
- He described work on the repository and SABATH
- This involved two existing AI models CloudMask and OSMIBench
- Shantenu Jha asked about the number of inferences per second.
- From MLCommons Science Working minutes, we find for OSMIBench
- On Summit, with 6 GPUs per node, one uses 6 instances of TensorFlow server per node. One uses batch sizes like 250K with a goal of a billion inferences per second
Argonne
- Continue to work on Second-order Optimization Framework for Deep Neural Networks with Communication Reduction
- Baixi Sun presented the details
- He introduced quantization to lower precision QSGD which gives encouraging results, although In one case quantization method failed in the eigenvalue stage
- We removed Rick Stevens from the Google Group
- Geoffrey mentioned his ongoing work on improving shuffling using Arrow vector format; he will share the paper when ready
Indiana
- Vikram gave the presentation without slides
- Continuing study of needed training set for the Ions confinement surrogate Probing Accuracy-Speedup Tradeoff in Machine Learning Surrogates for Molecular Dynamics Simulations | Journal of Chemical Theory and Computation
- New dataset to explore soft labels reflecting computational uncertainty to reduce errors
Rutgers
- Shantenu presented
- Nice paper on surrogate classes with Wes Brewer, who works with Geoffrey on OSMIBench
- Mini-apps for each of the 6 motifs that need FAIR metadata
- 5 motifs use surrogates; one generates them
- He described an interesting workshop on molecular simulations
- He noted that Aurora training trillion parameter foundation model for science
- LLMs need 10 power 8 exaflops: Need to optimize!
- Vikram noted SIMULATION INTELLIGENCE: TOWARDS A NEW GENERATION OF SCIENTIFIC METHODS
Tennessee
- Piotr presented slides
- CosmoFlow on 8 GPUs is running well
- He introduced the MiniWeatherML mini-app
- CUDA-aware pointers must be explicitly specified in the FAIR schema
- Test in PETSc leaves threaded MPI in an invalid state
- Alternative MPIX query interface varies between MPI implementations
- GPU Direct copy support is optional
- SABATH system is moving ahead with a focus on adding MPI support
- Piotr is now the PI of this project at UTK. We removed Cade Brown, Jack Dongarra, and Deborah Penchof from the Google Group
8.10 - Meeting Notes 05-29-2023
Meeting Notes from 05-29-2023
Minutes of SBI-FAIR May 29, 2023, Meeting
Present: Geoffrey Fox, Xiaodong Yu, Baixi Sun. Piotr Luszczek,
Virginia
- Comment on Surrogates produced by generative methods versus those that map particular inputs to particular outputs. In examples like experimental physics apparatus simulations, you only need output and not input. Methods need to sample output data space correctly.
- Geoffrey also described earlier experiences using second-order methods and least squares/maximum likelihood optimizations for physics data analysis. One can use eigenvalue/vector decomposition or the Levenberg-Marquardt method.
Tennessee
- SABATH student continuing over summer
- New surrogate MiniWeatherML is not PyTorch Tensorflow from Oak Ridge
- “Hello World” for weather. https://github.com/mrnorman/miniWeatherML
Argonne
- Xiaodong summarized the situation, and Baixi gave a detailed presentation
- Working on reducing data size, but compression technology seems difficult
- The error-bounded approach doesn’t seem to work very well, and so Argonne are investigating other methods. There is currently no method that preserves good accuracy and gives significant reduction.
- Looking at the performance of first and second-order gradients
- What can you drop in second order method – lots of data are irrelevant but not what current lossy compression seems to be doing
- Model parallelism for calculating eigensystems and then Data parallelism
8.11 - Meeting Notes 04-03-2023
Meeting Notes from 04-03-2023
Minutes of SBI-FAIR April 3 2023, Meeting
Present: Geoffrey Fox, Gregor von Laszewski, Przemek Porebski, Piotr Luszczek, Kamil Iskra, Xiaodong Yu, Baixi Sun. Vikram Jadhao, Margaret Lentz (DOE),
Regrets: Shantenu Jha
**DOE **had no major announcements but reminded us of links
- US Department of Energy Office of Science
- ASCR Funding Opportunities | U.S. DOE Office of Science (SC)
- Also noted that No Cost extensions were needed six months before the official end due to the heavy load at the DOE Chicago office.
- Margaret noted that University responses to Earthshot should read the laboratory call as well.
Virginia Geoffrey summarized activities (Slides 1-5) with a new Virtual Tissue surrogate using UNet and periodic boundary conditions. We are investigating new ideas that can describe functions with a wide dynamic range. Virginia is responsible for final deployed surrogates and building a team with Undergraduates, Researchers, and Ph.D. students. Students find experience educational, as we discovered in a collaboration with New York University. Przemek Porebski is joining the Virginia team with experience in computational epidemiology, and software engineering. Przemek introduced himself. Virginia also covered the status of MLCommons benchmarks, including new ones OSMIBench and FastML.
Rutgers Shantenu was unable to attend but prepared slides and briefed them to Geoffrey, who presented them to him (Slides 6-10). These summarize the current status with a list of the six classes of surrogate problems identified as important. Shantenu compared the training samples for surrogates with that found for LLM’s. He proposes to develop mini-apps (benchmarks) covering the range of key features exhibited by surrogates.
Vikram gave Indiana University’s Presentation with a careful analysis of accuracy as a function of
- Dataset size showing error plateaus at acceptable values at a sample size of around 2000.
- The boundary versus internal points
- Sensitivity to removing selected features and how many removed points were needed for acceptable answers. Here result depended on the particular feature and measured generalizability of the network.
- There is a publication under review.
Argonne’s new results were described by Baixi where the team was busy preparing a paper for SC23.
- They continued the study of second-order methods showing a broadcast was time-consuming, taking 48% of the time on 64 GPUs.
- The message sizes were not large and in a region where latency was important.
- They used lossy compression and studied the outliers in this.
- Note the last meeting’s presentation introducing the K-FAC method.
Piotr described Tennessee’s work with
- Focus on SABATH tested on three applications. It is nearly ready to be used by Virginia
- They have identified a new graduate student and need to modify the contract where Margaret gave key advice.
8.12 - Meeting Notes 02-27-2023
Meeting Notes from 02-27-2023
Minutes of SBI-FAIR February 27 2023, Meeting
**Present: **Geoffrey Fox, Piotr Luszczek, Gregor von Laszewski, Kamil Iskra, Xiaodong Yu, Baixi Sun. Vikram Jadhao,
We discussed modifying our simple summary describing the status and plans for the project to add a discussion of the timeline. Virginia did theirs as an example on slide 2.
Indiana
Vikram discussed recent activity, responding to referee comments on their recent paper.
Virginia
Geoffrey noted two new surrogates: A diffusion surrogate https://arxiv.org/abs/2302.03786 with James Glazier and J. Quetzalcoatl Toledo-Marin; a computational fluid dynamics surrogate https://code.ornl.gov/whb/osmi-bench from Oak Ridge
Geoffrey described issues arising from the diffusion surrogate above. We are trying to understand how deep learning can work for problems with a large range of input or output values. Examples could be covid, flu counts, images with a wide range of illumination, finding surrogate solutions where function values often range over several orders of magnitude, and one is interested in both large and small values. This range of values is seen over spatial values (images) or time values (time series)
However, this doesn’t seem to work properly in deep learning, where the activation value is 1. The weights cannot adjust to different sizes of input values, so one cannot see the nonlinearity of activation in values over the full range. Naively the DL will choose weights, so activation nonlinearity only really impacts a portion of the value range. One can think of many approaches
a) replace value by value**n for n < 1 including log value
b) scale activation value by an average value (found from a coarser scale if labeled by space as in an image)
c) Mixture of experts with different values of activation for each expert such as 0.001 0.01 0.1 1
Tennessee
Piotr reported that the SABATH project had a new student and was ramping up.
Argonne
Baixi discussed second-order optimization using Kronecker-factored Approximate Curvature K-FAC, which significantly outperforms standard Stochastic Gradient Descent. This is coupled with compression to reduce communication costs.
8.13 - Meeting Notes 01-30-2023
Meeting Notes from 01-30-2023
Minutes of SBI-FAIR January 2, 9, and 30 2023, Meetings
January 2 2023:
**Present: **Deborah Penchoff, Shantenu Jha, Geoffrey Fox, Piotr Luszczek, Gregor von Laszewski
We discussed producing a simple summary (roughly one slide per institution) describing the status and plans for the project. Virginia, UTK, and Rutgers made a draft which will be expanded before our January 30 meeting with Margaret. These should mention inter-institution collaborations. We continued on January 9
January 9 2023:
**Present: **Geoffrey Fox, Kamil Iskra, Xiaodong Yu, Baixi Sun. Vikram Jadhao, Gregor von Laszewski
Based on the earlier meeting, Argonne and Indiana produced summary pages which we iterated to include collaborations to deposit surrogates in the repository.
January 30, 2023:
Present: not recorded, but all institutions represented
We gave our presentation and followed with a discussion with Margaret. She noted recent DOE calls with useful links
https://public.govdelivery.com/accounts/USDOEOS/subscriber/new
https://science.osti.gov/ascr/Funding-Opportunities
She stressed the importance of establishing a timeline. We should discuss at the next meeting.
We didn’t decide on a cadence for her presence at our meetings.
8.14 - Meeting Notes 01-05-2023
Meeting Notes from 01-05-2023
Minutes of SBI-FAIR May 1, 2023, Meeting
Present: Geoffrey Fox, Gregor von Laszewski, Przemek Porebski, Kamil Iskra, Xiaodong Yu, Baixi Sun. Vikram Jadhao, Piotr Luszczek,
Regrets: Shantenu Jha
Virginia Geoffrey noted continued progress with the new Virtual Tissue surrogate using UNet and periodic boundary conditions. Interesting that UNet mimics multigrid PDE methods. Przemyslaw still disentangling from other work but will start very soon. Several (50 in 2 weeks) undergraduate and incoming graduate student research requests. Surrogate OSMIBench progress and will integrate with SABATH. Geoffrey asked what surrogates are available to work on now.
Rutgers
Not presented
Indiana University
Vikram discussed progress. Ions in confinement code will be sent to UVA. Discussed sensitivity to training data showing the need for some but not all samples in a region.
https://pubs.acs.org/doi/10.1021/acs.jctc.2c01282 and PDF is
Studied interpolation; extend to extrapolation
Speedup study – the factor of 2 if one drops every other point and replace them by a small fraction of these interpolations
Argonne
The SOLAR paper was rejected.
Baixi presented their new results with a focus on data compression (for second-order optimization)
Aggregate Broadcast as previously latency dominated
Float32 versus Float64 inversion error (eigensolution versus inversion)
Some tasks are sensitive to precision.
Submitted to SC23; will share with people
Communicated Light Source Surrogates PtychoNN and AutoPhaseNN to the FAIR main repository. Baixi asked Dr. Cherukara (from ANL) and got permission about which can be available to the public.
- Currently, PtychoNN has the Code, trained model weights, training, and test data on GitHub: https://github.com/mcherukara/PtychoNN.
- AutophaseNN has Code, trained models, and test data available on GitHub: https://github.com/YudongYao/AutoPhaseNN.
Specifically, they implemented PytchoNN using PyTorch Distributed Data-Parallel (DDP)
See Onedrive FAIR Or please use this google drive link:
https://drive.google.com/drive/folders/1c2HGFBiymJUu9yaUTW5K-dIOoemxOfjN?usp=sharing These have the same readme and Python files
Tennessee
Piotr presented CUDA 10 versus CUDA 11
SABATH Cosmoflow small dataset working. Move to
- Earthquake
- OSMIBench
Gregor described progress with Friday May 14 1 pm meeting with Wes Brewer
Gregor recommends exchanging Docker or Singularity definition files
SABATH could create the container image
8.15 - Meeting Notes 11-28-2022
Meeting Notes from 11-28-2022
Minutes of SBI-FAIR November 28, 2022, Meeting
Present: Kamil Iskra, Xiaodong Yu, Deborah Penchoff, Shantenu Jha, Geoffrey Fox, Piotr Luszczek, Baixi Sun. Vikram Jadhao, Gregor von Laszewski and Margaret Lentz from DOE
Preparations/drafts: Nov 28 2022 DOE Project Review Preparations
Actually delivered presentations are has on the first slide links to individual presentations in the order
- Virginia
- Tennessee
- Argonne
- Rutgers
- Indiana
Margaret emphasized the need for continued interaction and we scheduled the next meeting with Margaret on January 30, 2023.
8.16 - Meeting Notes 10-31-2022
Meeting Notes from 10-31-2022
Minutes of SBI-FAIR October 31, 2022, Meeting
Present: Kamil Iskra, Xiaodong Yu, Peter Beckman, Deborah Penchoff, Shantenu Jha, Geoffrey Fox, Piotr Luszczek, Baixi Sun. Vikram Jadhao, Gregor von Laszewski
Updates
Virginia
Geoffrey discussed
- The transfer of the DOE grant is completed
- The Tsunami surrogate (see last meeting) is finished while the diffusion-based surrogate is still being finalized
- Rough draft of the diffusion model for cell simulations GENERALIZATION AND TRANSFER LEARNING IN A DEEP DIFFUSION SURROGATE FOR MECHANISTIC REAL-WORLD SIMULATIONS. Interesting is the study of dataset sizes 5000-400,000 and the importance of dealing with the large numeric range in computed values
- We discussed Margaret Lentz’s request for a project presentation
- Draft after SC22 with final presentation November 28 1-2 pm finalized with Margaret
- Some integrating slides and then 4-6 from each team covering past work; remaining work in the grant; what to do after the grant
- Pete reminded us not to forget FAIR!
- Geoffrey will make a plan
Argonne
- Their VLDB2023 paper: “SOLAR: A Highly Optimized Data Loading Framework Training CNN-based Scientific Surrogates,” was discussed
- This paper looks at the training of 3 surrogates and addresses the overhead of the I/O disk access that dominates the performance
- They compare with PyTorch Data Loader and the NoPFS paper [2101.08734] Clairvoyant Prefetching for Distributed Machine Learning I/O from Torsten Hoefler at the last SC meeting. This does optimized prefetching
- The shuffle is optimized to minimize redistribution and this leads to an improvement factor of 3.5 over NoPFS and 24 over default PyTorch \
Tennessee
Piotr reported that Cade Brown has left and they are hiring a replacement.
Rutgers
Shantenu reported
- That their team had identified 6 categories with AI enhancing HPC and they were studying performance
- He returned to topic of Large Language models LLM that can be effective in chemistry,
Indiana University
Vikram reported that
- They were continuing study of accuracy and robustness as last time as well as
- Dataset size
- Ensemble issues
- Definition of speedup
8.17 - Meeting Notes 09-26-2022
Meeting Notes from 09-26-2022
Minutes of SBI-FAIR September 26, 2022, Meeting
Present: Kamil Iskra, Xiaodong Yu, Deborah Penchoff, Shantenu Jha, Geoffrey Fox, Piotr Luszczek, Baixi Sun. Vikram Jadhao, Gregor von Laszewski
Updates
Virginia
Geoffrey discussed
- The transfer of the DOE grant is still making progress
- He noted two nearly completed new surrogates
- paper on Tsunami simulation surrogates entitled “Forecasting tsunami inundation with convolutional neural networks for a potential Cascadia Subduction Zone rupture”
- Rough draft of the diffusion model for cell simulations GENERALIZATION AND TRANSFER LEARNING IN A DEEP DIFFUSION SURROGATE FOR MECHANISTIC REAL-WORLD SIMULATIONS. Interesting is the study of dataset sizes 5000-400,000 and the importance of dealing with the large numeric range in computed values
- He summarized the MLCommons status with the move to continuous (rolling) submissions rather than fixed date submissions
Indiana University
- Vikram presented some of his recent work
- He studied sensitivity to input training set showing some dramatic effects from seemingly small changes – removing one value of electrolyte concentration c
Tennessee
Piotr reported
- There was a Data Challenge at Smoky Mountain meeting with a smaller version of the Cloudmask dataset from MLCommons 2022 Challenge 6: SMCEFR: Sentinel-3 Satellite Dataset « SMC Data Challange 2021
- Two Submitted papers: one on Performance Surrogate and the other a SABATH paper at HPEC Conference IEEE HPEC 26th Annual 2022 IEEE High Performance Extreme Computing Virtual Conference 19 - 23 September 2022
- paper and presentation Deep Gaussian process with multitask and transfer learning for performance optimization
- Questions included reproducibility and overheads from using FAIR metadata
- It was asked if SABATH recorded training time; it does record loss versus epoch number.
- Tennessee will give a detailed presentation on SABATH next time.
Rutgers
Shantenu reported
- Drug and Quantum surrogates
- He noted a new DOE $25M award for climate surrogates revisiting the startling Oxford paper https://iopscience.iop.org/article/10.1088/2632-2153/ac3ffa/meta and https://arxiv.org/pdf/2001.08055v1
- Work with Indiana University was continuing with efforts to get system running on Summit
- There was a discussion of Large Language models LLM and DOE interest in using them on scientific literature. There is a challenge with the current $10-100 million computing training cost possibly reaching a billion dollars.
Argonne
- Xiaodong Yu discussed the ASPLOS paper which was unfortunately rejected
- Baixi presented their results commenting on referee remarks
- One question prompted observation that surrogate MODEL sizes are comparatively small
- Another question was answered by noting that scheduling was a one-time cost
- In some cases their custom training order outperformed the baseline training
8.18 - Meeting Notes 08-15-2022
Meeting Notes from 08-15-2022
Minutes of SBI-FAIR August 15, 2022, Meeting
Present: Kamil Iskra, Xiaodong Yu, Deborah Penchoff, Shantenu Jha, Geoffrey Fox, Piotr Luszczek, Baixi Sun.
Apologies Vikram Jadhao,
Updates
Virginia
Geoffrey discussed
- The transfer of the DOE grant is making progress
- He is continuing his study of Foundation models by collecting common applications using similar deep learning systems
- He summarized the MLCommons status answering some questions noting that MLCommons collects surrogates and non-surrogate benchmarks
- Geoffrey will send Shantenu notice about MLCommons meetings
Gregor
- contacted Rutgers for help, but due to staff changes that effort was shifted to Summit support team. Activity in progress.
Rutgers
Shantenu reported
- Work with Indiana University was delayed as JCS Kadupitiya has graduated from IU and was hired by Microsoft
- Improving AI for Science Chapter with AI-linked workflows for a new publication with performance
Argonne
- Xiaodong Yu discussed the ASPLOS paper and will send an improved version in 2 weeks
- There are performance issues addressed with microbenchmarks
- Baixi presented their results optimized over epoch and batch
- This does not change results much even though the update order is different
- Schedule by access performance or load balance
- 4.2 to 5.8 speedup up to 64 processes
- Looking at scalability
- Other surrogates are AutophaseNN and BraggNN
Indiana University
Reported by email
- Starting Fall 2022, a new PhD student Fanbo Sun and a new postdoc Wenhui Li will work 50% on this project. Postdoc starts Sep 1.
- Soft labels: Continuing to explore the soft labels idea and how it reduces training set sizes. Planning a submission sometime this year. One paper submitted last year on this topic is still under review.
- Time series surrogate: With the postdoc, we will be working to extend the RNN operator to tackle NVT ensemble and larger number of particles.
Tennessee
Piotr reported
- Cade will come back plus a new Ph.D. student
- Two Submitted papers: one on Performance Surrogate and the other a SABATH paper
- Third paper to Data Challenge
8.19 - Meeting Notes 06-27-2022
Meeting Notes from 06-27-2022
Minutes of SBI-FAIR June 27, 2022, Meeting
Present: Kamil Iskra, Deborah Penchoff, Vikram Jadhao, Shantenu Jha, Geoffrey Fox, Piotr Luszczek, Baixi Sun, Gregor von Laszewski
Updates
Virginia
- Foundation Models – collect surrogates
- Need a group DOE report. Use last year’s approach with a common response initialized by Piotr https://docs.google.com/document/d/19cbBj2IMIMa_HUPAUaREy3zRYBQfEoS5hCmM7wyU48c/edit?usp=sharing
- Note plans went a bit different as due to transfer Indiana and Virginia were not asked for annual reports
Tennessee
- SABATH software
- MLCommons Paper ISC Piotr Luszczek went and did not get Covid. BOF presentation from Piotr and H3 conference H3 workshop report from Jeyan Thiyagalingam.
Rutgers
- Vincent Pascuzzi has a prototype software system running with JCS Kadupitiya
- Davis DOE AI meeting is July 26-28
- Train Foundation models
- Performance of workflow
- Omniverse
**Indiana **
- Hire postdoc now that JCS Kadupitiya has graduated and hired by Microsoft
- Soft label paper progressing
- Using Tensorflow for simulation
Argonne
- Kamil Iskra described publication plan of a paper to ASPLOS and poster to SC
- Baixi noted June 30 abstract deadline and gave the presentation
- 1.3 TB dataset
- I/O takes ~81% when run on 8 nodes and 64 GPUs on ThetaGPU
- Clump data and load balance to decrease load time gives a factor of 2.16 speedup
- Use Memory not SSD for storage
- Gregor suggested compressing data in shared memory
- Global arrays and RDMA
8.20 - Meeting Notes 05-23-2022
Meeting Notes from 05-23-2022
Minutes of SBI-FAIR May 23, 2022, Meeting
Present: Kamil Iskra, Deborah Penchoff, Vikram Jadhao, Shantenu Jha, Geoffrey Fox, Xiaodong Yu, Piotr Luszczek, Baixi Sun, Gregor von Laszewski
Updates
Virginia
- Geoffrey described substantial progress with Science working group of MLCommons which should have reached first base on June 1 at an ISC BOF
- The diffusion equation surrogate work with Javier Toledo and James Glazier is being written up.
- He also commented on Argonne shuffling performance and use of Big Data collective shuffle primitives that work on disk and memory.
Tennessee
- Cade Brown is on internship with NVIDIA
- Piotr gave the presentation describes the nice progress with SABATH system introduced by Cade last month.
- SABATH is now available with two applications
- Keras MNIST
- Cloudmask-0 extended from work of UK group of Tony Hey
- SABATH would cache data locally
- Tensorboard visualization support was described
- Add PyTorchsupport to current Tensorflow plus new applications. \
Rutgers
- Meeting with the Indiana group (Vikram) on adaptive training
**Indiana **
- Working with Rutgers to agree with last bullet!
- Devising strategy to minimize needed training size
- JCS Kadupitiya in Vikram’s group got his Ph.D. and the Luiddy outstanding research award. He is off to work for Microsoft.
Argonne
- Baixi gave the Argonne presentation after introduction by Xiaodong
- They are debating between HDF5 or Binary storage
- Changing the I/O middleware to be based on parallel HDF5
- Test done on 16 GPUs corresponding to 2 nodes
- Execution time doesn’t depend much on Batch size. Geoffrey suggested that indicates GPUs not fully utilized so smaller computation does not exploit all internal GPU parallelism
- Baixi reviewed the problems with shuffle being needed every epoch and the challenge when data size large and will not fit in memory and needs disk (small datasets fit into memory)
- The Lustre file system used is bad for small randomly accessed files; typically each image is one file
- The load is manly read with some writes
- The shufflings are all precalculated and the redistribution needed (MPI AllScatter/gather) can be represented as a graph which is imbalanced
- Computation and Data movement are traded off with heuristic solution near to the true minimum
- Parallel HDF5 (using MPI-IO) supports multiple MPI processes
8.21 - Meeting Notes 04-25-2022
Meeting Notes from 04-25-2022
Minutes of SBI-FAIR April 25, 2022, Meeting
Present: Kamil Iskra, Deborah Penchoff, Vikram Jadhao, Shantenu Jha, Geoffrey Fox, Xiaodong Yu, Piotr Luszczek, Cade Brown, Baixi Sun, Jack Dongarra
Updates
Virginia
- Discussed continued work on diffusion surrogate with Glazier and Javier Toledo (Edmonton)
- Discussed Fusion surrogate benchmark from Lawrence Livermore
Tennessee
- Cade Brown presented an update
- Discussed Sentinel 3 benchmark based on UK Cloudmask from MLCommons
- Then discussed FAIR Benchmark platform SLIP which is has been extended to become SABATH
- Described report structure
- Model format - how universal is this
- Has done UK cloudmask and looked at TEvol (2 MLCommons benchmarks)
- Deal with Jupyter notebooks with nbconvert
- Add callbacks to model.fit
- How to do FAIR
- Use Json
- Relation to SciML-Bench GitHub - stfc-sciml/sciml-bench: SciML Benchmarking Suite for AI for Science and MLCube from MLCommons
Rutgers
- The IPDPS paper was accepted. This isn’t the final version, but the only publicly available version currently is [2104.04797] Coupling streaming AI and HPC ensembles to achieve 100-1000x faster biomolecular simulations
- Discussed Adversarial autoencoders and use of Alphafold which is expected to do better
- Summit difficult due to IBM containers
- Noted continued study of “2 billion” paper (renamed “Building high accuracy emulators for scientific simulations with deep neural architecture search” https://arxiv.org/pdf/2001.08055.pdf)
- Survey paper
- Noted Proxima by Ian Foster Proxima | Proceedings of the ACM International Conference on Supercomputing
**Indiana **
- Working on scaling recurrent neural net surrogate https://doi.org/10.1088/2632-2153/ac5f60 to more particles
- Ph.D. student JCS Jcs Kadupitiya will defend thesis.
Argonne
- Baixi presentation
- Described distributed training shuffling problem as a graph
- Cost of training has large data loading time
- Studied increasing standard deviation/mean by redistribution over nodes
- Address Imbalance data loading by moving computetasks to other nodes
- Note large compute variance over GPUs even if batch size fixed, which seems surprising – why are some GPUs slow?
8.22 - Meeting Notes 03-19-2022
Meeting Notes from 03-19-2022
Minutes of SBI-FAIR March 19, 2022, Meeting
- Present: Kamil Iskra, Vikram Jadhao, Shantenu Jha, Geoffrey Fox, Xiaodong Yu, Piotr Luszczek, Cade Brown, Baixi Sun, Gregor von Laszewski
Updates
Rutgers
A postdoc left unexpectedly and so the surrogate classification work was delayed. The integration of Rutgers software into Vikram’s work is proceeding and will be tested with a Summit allocation.
Indiana
Vikram discussed a surrogate paper accepted by Machine Learning: Science and Technology journal https://doi.org/10.1088/2632-2153/ac5f60. This evolves a modest collection of particles in for example the Lennard-Jones potential obtaining good results with time steps 4000 times that of classic solvers. He also presented at multiple APS sessions. He noted other work using Tensorflow to perform simulations – a collaboration with another Indiana Engineering faculty.
Virginia
Gregor presented on the status of the MLCommons benchmark stressing the difficulties in reconciling GitHub and Jupyter notebooks. Geoffrey noted that these were not quite what you wanted as a scientific electronic notebook as they didn’t support sharing of modified versions and the management of multiple Jupyter notebooks. For example, this project produced 450 notebooks and it is not even easy to search as traditional Google search fails on notebooks.
Gregor also discussed timing tools
Tennessee
Piotr described progress in integrating MLCommons ontologies into the FAIR metadata system. He also noted problems in defining how to run SciML benchmarks with Horovod. Tennessee also submitted a challenge to the Smoky Mountain conference based on Satellite images generalizing the SciML CloudMask benchmark
Argonne National Laboratory
Xiaodong introduced the Argonne study of shared I/O. The need for global shuffling at each epoch is potentially an I/O problem but their approach gave almost a factor of 10 improvement (11.4 seconds reduced to 1. seconds).
Baixi gave a detailed discussion with his usual excellent presentation.
Geoffrey and Gregor noted the practical challenge of I/O in University shared file systems with both the Earthquake code and an examination of a regular MLPerf benchmark where cloud I/O was much faster than the academic shared file system. The latter problem can be addressed by copying to local disks. Execution from those is a little faster than the cloud numbers.
8.23 - Meeting Notes 02-14-2022
Meeting Notes from 02-14-2022
Minutes of SBI-FAIR February 14 2022 Meeting
- Present: Kamil Iskra, Vikram Jadhao, Geoffrey Fox, Deborah Penchoff, Xiaodong Yu, Piotr Luszczek, Cade Brown, Baixi Sun, Gregor von Laszewski
Updates
Tennessee
A new team member Cade Brown gave a fascinating talk CadeBrown-notes-SBI_Schema. Cade Brown is a new ICL student tasked with designing a schema and tooling for installing, running, and benchmarking ML models. He showed examples using MLCommons Science benchmarks CloudMask and STEMDL. There will be a public website from which you can search models, datasets, and results and run examples. He discussed use of JSON rather than XML and the use of Google’s Firebase JSON database tool. There was a discussion of the sustainability of Firebase (as you need to pay) and the use of containers.
Geoffrey noted synergy with MLCommons Science Data working group Science Working Group | MLCommons, the Research Data Alliance and Christine KIrkpatrick
Argonne National Laboratory
Argonne described the continued work on understanding the performance of distributed training already discussed in the last four meetings. Today’s discussion focussed on I/O and included a talk by Baixi which as always was very informative. I/O is a major bottleneck alleviated by caching in either SSD and/or CPU memory. There is a plan for a Parallel I/O and hdf5 paper at SC22. The Hoefler paper at SC21 Clairvoyant prefetching for distributed machine learning I/O | Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis has a simulator that ANL used in this analysis. Shuffling is major difficulty as requires access to all the data. There is a fast local version but it is not as good an algorithm as the usual global shuffle. Currently, dataset is 22 GB but it can increase. \
Indiana
Vikram reported that his surrogate was ready to deploy and that he has received a Summit allocation to support its training. He had met with Shantenu. He sent Cade Brown a couple of links to a repository that hosts their ML surrogate model and the simulation code used to generate datasets to train and test this model. Hopefully, this surrogate can serve as a test model for the system he is building.
https://github.com/softmaterialslab/nanoconfinement-md/tree/master/python
https://github.com/softmaterialslab/nanoconfinement-md/
You can see the surrogate in action, by launching the tool:
https://nanohub.org/tools/nanoconfinement/
Virginia
Progress continues with surrogate for discussion solver. We are writing a second paper on this. Gregor discussed progress with compression.
8.24 - Meeting Notes 01-10-2022
Meeting Notes from 01-10-2022
Minutes of SBI-FAIR January 10 2022 Meeting
Present: Kamil Iskra, Vikram Jadhao, Geoffrey Fox, Deborah Penchoff, Xiaodong Yu, Jack Dongarra, Shantenu Jha, Piotr Luszczek, Baixi Sun, Gregor von Laszewski
Updates
Tennessee
Piotr reported UTK’s continued progress with the FAIR technology in his presentation with a discussion of the ontology needed for SciML and extensions to MLCommons. The choice of YAML versus XML and TOML was discussed. There was a discussion between Piotr and Gregor about that indicated that the YAML format is not sufficient to encode the surrogate and the hardware used for it. An alternative was discussed where one encodes endpoints in the YAML and these endpoints have the detailed metadata/Schema. This is natural in examples that use PyTorch or Tensorflow which could have customized sub-ontologies. Gregor suggested circulating an example to identify if YAML would be nevertheless good enough. The performance surrogate is running on Summit.
Argonne
Argonne described the continued work on understanding the performance of distributed training already discussed in the last three meetings with the 2 models, Horovod and the Mirrored Strategy, for ptychoNN surrogate. Baixi new slides are at They are using the latest model from PtychoNN team and testing on the large diffraction and real space data on the 2 distributed training models. Horovod did better on 4, 8 GPU’s; Mirrored on 1,2 GPU’s. They implemented Pytorch DDP to profile and analysis the performance.
Rutgers
- This continued discussion from last time on work with Vikram on software
- .Progress on Quantum computing surrogate with Ian Foster
- Shantenu also updated work on categorizing surrogates. \
Indiana
Vikram reported an update on the time series molecular dynamics surrogate although not using the soft (adding in simulation errors) optimization.
Virginia
Geoffrey was distracted by the poor performance of his home internet (now corrected) and did not report solid progress on his diffusion equation solver
8.25 - Meeting Notes 10-21-2021
Meeting Notes from 10-21-2021
Minutes of SBI-FAIR October 25 2021 Meeting
Present: Kamil Iskra, Vikram Jadhao, Geoffrey Fox, Deborah Penchoff, Xiaodong Yu, Jack Dongarra, Shantenu Jha, Piotr Luszczek, Baixi Sun, Gregor von Laszewski
Updates
Tennessee
Piotr reported that paper submitted to IPDPS; and metadata (FAIR) work is continuing
Virginia
Geoffrey has summarized 4 possible MLCommons Science Datasets that could be useful for FAIR studies. See recent Argonne preprint
Indiana
Vikram Jadhao described his new surrogate paper [2110.14714] Designing Machine Learning Surrogates using Outputs of Molecular Dynamics Simulations as Soft Labels and quoting from abstract “Here, we show that statistical uncertainties associated with the outputs of molecular dynamics simulations can be utilized to train artificial neural networks and design machine learning surrogates with higher accuracy and generalizability. We design soft labels for the simulation outputs by incorporating the uncertainties in the estimated average output quantities and introduce a modified loss function that leverages these soft labels during training to significantly reduce the surrogate prediction error for input systems in the unseen test data. The approach is illustrated with the design of a surrogate for molecular dynamics simulations of confined electrolytes to predict the complex relationship between the input electrolyte attributes and the output ionic structure. The surrogate predictions for the ionic density profiles show excellent agreement with the ground truth results produced using molecular dynamics simulations.”
Rutgers
- Collaboration with Vikram has started
- Classification of surrogates introduced 6 classes and analyzed many new papers
- Gordon Bell submission involved Caltech + DOE Labs + San Diego and used surrogates at multiple levels – it studied how to balance effort between them. The application concerned Delta Covid.
Argonne
Kamil and Xiaodong described the continued work on understanding the performance of distributed training already introduced last month. Baixi gave the presentation . Next month will see a new dataset and new results.
Hyperparameters were tuned for ptychoNN surrogate on Horovod and the Mirrored Strategy.
The current approach is synchronous but will look at asynchronous methods.
We agreed on the next meeting date November 29.
8.26 - Meeting Notes 09-27-2021
Meeting Notes from 09-27-2021
Minutes of SBI-FAIR September 27 2021 Meeting
Present: Kamil Iskra, Vikram Jadhao, Geoffrey Fox, Deborah Penchoff, Xiaodong Yu, Jack Dongarra, Shantenu Jha, Piotr Luszczek, Pete Beckman, Baixi Sun, Gregor von Laszewski
Updates
Indiana/Virginia
Vikram has a new surrogate and is finalizing a paper on it. He will talk to Shantenu soon.
Rutgers
Shantenu affected by hurricane
- Developing 3 layer simulations with surrogate at each level
- ML driven HPC motifs/patterns identified in research to be reported at November meeting
- DeepDriveMD ensemble is one example
- climate science simulations gives surrogates that select best simulation
- Link with observation link seen in climate, materials and biomolecular science
University of Tennessee
- Workshop in April 4-7 2022 at UTK
- Performance surrogate paper to IPDPS; excellent speedup but not 2 billion
- FAIR ontologies will resume after this paper
Argonne
- Yu introduced their GPU scheduling work and investigation of the surrogate model training change scalability
- Baixi Sun gave a detailed presentation on Distributed Training On PtychoNN
- Utilized the Horovod framework on ptychoNN model.
- Tested the Horovod performance for different number of GPUs on single node and multiple nodes using Ring All-Reduce
- Tried Mirrored Strategy framework on ptychoNN model.
- Tested the performance for different number of GPUs on single node.
- Debugging of the Mirrored Strategy framework for distributed training.
- Presented performance numbers with MNIST and ptychoNN
- Updated our versions of code on our gitlab repository and wiki documentation.
- Links for more details are: 8. This is the official documentation for Horovod: Horovod with Keras — Horovod documentation . 9. And this is the thetaGPU Horovod tutorial: Distributed training on ThetaGPU using data parallelism | Argonne Leadership Computing Facility . 10. This is the official documentation for Mirrored Strategy: Multi-GPU and distributed training (Section “Single-host, multi-device synchronous training”). 11. To be specific, the code I ran on thetaGPU is currently in our private Gitlab repository: https://gitlab.com/SBI-HPC/benchmark_suite/-/tree/main/ptychography . (Please note that for Mirrored Strategy I am currently debugging on it so the latest stable version of code has not committed yet, will come soon!). 12. The guidance of using those code on thetaGPU is written in the Gitlab wiki: https://gitlab.com/SBI-HPC/benchmark_suite/-/wikis/PtychoNN-Distributed-Training-on-ThetaGPU.
8.27 - Meeting Notes 08-30-2021
Meeting Notes from 08-30-2021
Minutes of Meeting August 30, 2021
Present: Kamil Iskra, Vikram Jadhao, Geoffrey Fox, Deborah Penchoff, Xiaodong Yu, Jack Dongarra, Shantenu Jha, Piotr Luszczek, Pete Beckman, Baixi Sun
Updates
- Rutgers: Progress with recruiting problems. Highlighted a new paper https://doi.org/10.1021/acs.jcim.8b00839 on molecular benchmarks from Benevolent AI GuacaMol: Benchmarking Models for De Novo Molecular Design. Peter Coveney Company in London
- Tennessee continues work on the performance surrogate model. Tune hyperparameters. Build from small runs. Report in October. Works on simulations or data analytics. Unlike ATLAS aimed at problems with runs that take a large time
- **Argonne. **Pete noted by email a new paper Why AI is Harder Than We Think with a cautionary tale.
- Baixi Sun from Washington State University was introduced as a new student on project
- Xiaodong discussed their 3 use cases. Convert notebooks to python scripts and run in multinode fashion
- Using ALCF the first usage mode is based on Jupyter notebooks and second usage mode is batch
- ALCF likes Jupyter notebooks. Also note Jupyter notebooks at ORNL
- Indiana/Virginia. Vikram Jadhao presented on surrogates for soft materials
- This reviewed highlights from the field and then focussed on his work
- Word surrogate not often used in field
- The review covered SorbNet from MInnesota, ab initio simulation from Toronto and pair correlation function of liquids from UIUC group Aluru
- Vikram’s application was confined electrolytes where surrogate relates structure to attributes
- Good use in education using nanoHUB deployment
- Nice performance slide
- EXTENDED Predictions were not as good as original ones
- Need to quantify and improve accuracy – how? Average over all quantities but worse near the wall. COULD weight those points more in loss
- Common in surrogates, that error is dominated by “special” regions – boundaries, singularities etc. as work of Geoffrey with James Glazier on diffusion equation for cell modelling.
- Look at reducing needed training size
- Will evaluate using Rutgers software infrastructure
8.28 - Meeting Notes 07-26-2021
Meeting Notes from 07-26-2021
Minutes of Meeting July 26, 2021
Shantenu led a discussion of surrogates noting his work was delayed by a loss of a postdoc. Shantenu divided Surrogates into 3 areas
- **MLinHPC **as in Climate in Oxford paper [2001.08055] Building high accuracy emulators for scientific simulations with deep neural architecture search giving speedups over a billion but there are some curious features of this work. Directly replace full simulation but also can calculate potentials as in DeepMD https://arxiv.org/pdf/2005.00223.pdf where 80-90% of computational cost is potential computation.
- Docking with Austin Clyde and Argonne group (including Shantenu and Rick) [2106.07036] Protein-Ligand Docking Surrogate Models: A SARS-CoV-2 Benchmark for Deep Learning Accelerated Virtual Screening
- Factor of 10 no loss of accuracy
- NVIDIA helped on performance
- Docking with Austin Clyde and Argonne group (including Shantenu and Rick) [2106.07036] Protein-Ligand Docking Surrogate Models: A SARS-CoV-2 Benchmark for Deep Learning Accelerated Virtual Screening
- MLaboutHPC Here ML guides the simulation such as in choosing ensemble and his DeepDriveMD Westpahl algorithm shows a Factor of 100 compared to Anton
- Shantenu used a VAE but list of 7 methods on slide 8
- MLoutHPC where Shantenu gave one example where one optimizes campaign across scales using Reinforcement learning with Austin Clyde model at top
Shantenu presented PY2 and PY3 plans
In PY2 primary goals are:
- (mini-)Review of surrogates in HPC – Volunteers? See later
- Formalizing Performance measures (MLinHPC)
- Three scenarios discussed above: Climate, Docking, Potentials
- Experimenting with Performance (MLoutHPC)
- Use DeepDriveMD to support different surrogates (Table 1) for common physical model (system)
In PY3
- tackle (more) complex problem of MLoutHPC
AlphaFold2 (Google) and RoseTTaFold (Baker at Washington) DeepMind’s AI for protein structure is coming to the masses news BOTH released
CASP said protein folding solved from AlphaFold2 but RosettaFold is cheaper and as good as AlphaFold2. This could be an opportunity
Beckman noted we see a science transformation using FAIR Methodology.
Rick Stevens has challenged “How much did Go AI cost”
Dataset size is a serious issue.
- deepmind/alphafold: Open source code for AlphaFold. notes The total download size for the full databases is around 415 GB and the total size when unzipped is 2.2 TB. Please make sure you have a large enough hard drive space, bandwidth and time to download. We recommend using an SSD for better genetic search performance.
- Hurricane simulation will become inference
- Doe strategy train leave data where it is similar to medical federated learning
- Vikram noted that material science led to smaller datasets as just output final results and not the full trajectory
We discussed having a session at The Argonne Training Program on Extreme-Scale Computing (ATPESC) in 2022
Next month we will consider Implications for the project. Vikram and Shantenu volunteered
8.29 - Meeting Notes 06-29-2021
Meeting Notes from 06-29-2021
Minutes of Meeting June 29, 2021
Annual Report
This meeting focussed on getting the final version of the DOE annual report which was submitted the following day by each institution.
Next Meeting
Our meetings are 1 pm Eastern on the 4th Monday of each month
This implies Monday, July 25, 1 pm at zoom https://iu.zoom.us/j/2301429329
In the July meeting, Shantenu Jha will lead a discussion of surrogates, postponed from June
8.30 - Meeting Notes 05-24-2021
Meeting Notes from 05-24-2021
Minutes of Meeting May 24, 2021
Links for Today’s Meeting
Powerpoint of Argonne Talk 2021-05-SBI-ANL.pptx
PDF of Argonne Talk 2021-05-SBI-ANL.pdf
Present
Argonne: Min Si, Xiaodong Yu
**Indiana: **Geoffrey Fox, Vikram Jadhao, Gregor von Laszewski
Rutgers: Shantenu Jha
UTK: Jack Dongarra, Piotr Luszczek
Argonne Presentation
Xiaodong Yu’s described 3 surrogates being developed at Argonne
Application 1 **PtychoNN: Ptychographic Imaging Reconstruction phase reconstruction **
Here the challenge is to determine phases from Xray scattering data with paper. The surrogate is being extended to run using Horovod on the multi-GPU ThetaGPU system.
Application 2: Geophysical Forecasting
This involves LSTM forecast models combined with a neural architecture search NAS using deephyper in original paper which ran on Theta without GPUs.
Application 3: Molecular dynamics (MD) simulation
This is multiscale modeling of SARS-CoV-2 in the CANDLE project which received the 2020 ACM Gordon Bell Special Prize for High Performance Computing-Based COVID-19 Research.
Shantenu Jha was a co-author on their paper “AI-Driven Multiscale Simulations Illuminate Mechanisms of SARS-CoV-2 Spike Dynamics”.
Other Business We discussed adding material to the website.
Annual Report
We just received the request from DOE for an annual report abstracted below, We could discuss (unfortunately it is due before our next meeting) a common text that we could use as part of each report.
The Office of Advanced Scientific Computing Research (ASCR) within the Department of Energy Office of Science requests that you submit a Progress Report for the award listed below. To create and submit the Progress Report, please use the DOE Office of Science Portfolio Analysis and Management System (PAMS).
Task: Submit Progress Report (Link)
Due Date: 06/24/2021 5:00 PM ET
Reporting Period: 09/23/2020 - 09/22/2021
Next Meeting
Our meetings are 1 pm Eastern on the 4th Monday of each month
This implies Monday, June 28, 1 pm at zoom https://iu.zoom.us/j/2301429329
In the June meeting, Shantenu Jha will lead a discussion of surrogates.
8.31 - Meeting Notes 04-19-2021
Meeting Notes from 04-19-2021
Minutes of Meeting April 19, 2021
Links for Today’s Meeting
- Indiana Update plus Overall Project Remarks SBI-Meeting-IU-April19-2021
- Tennessee Update Presentation sbi20210419.pdf
Updates
- Argonne postponed their update to the next meeting and the other 3 sites gave updates.
- Indiana discussed SciMLBench from the UK with its first release and the related MLCommons Science benchmarking. With surrogates, Jadhao will work on the nanoengineering one in the Fall and Fox completed an initial study of a virtual tissue surrogate [2102.05527] Deep learning approaches to surrogates for solving the diffusion equation for mechanistic real-world simulations.
- Tennessee gave a comprehensive report covering their Surrogate Performance Model for Autotuning; their FK6D / ASGarD · GitLab project aimed at a later release of SCiMLBench and an insightful analysis of issues and needed ontologies for a FAIR approach to benchmark data. The discussion pointed out that FAIR does not address areas like validation, verification, and reproducibility. Piotr introduced broad categories: Hardware, firmware, dataset, software, measurements. We know from MLPerf that I/O specification and measurement are nontrivial. The mode of execution: capability or capacity(high-throughput) needs to be specified. Gregor noted complications from the use of containers that can hide software versioning. Christine Kirkpatrick’s Advancing AI through MLCommons to MLCommons Benchmark-Infra WG April 6 highlighted tension between the flexibility of free text and FAIR machine readability
- **Rutgers **Shantenu Jha discussed recent work by his group on computational performance. He pointed out a recent paper by Alexandru Iosup on GradeML: Towards Holistic Performance Analysis for Machine Learning Workflows
Discussion and Action Items
- We agreed to start two working groups on FAIR (coordinated by Piotr) and Surrogates (coordinated by Shantenu). The scope of both groups was unclear as yet and should be discussed in meetings
- There was a discussion of access to computers across the collaboration
- We discussed Surrogate Software and Benchmark software with work of Deep500 (Torsten Hoefler of ETH Zurich), GradeML, MLCube, SciMLBench mentioned. We need to relate it to FAIR
- We still need to implement SBI repository
- We agreed in the March meeting to enhance the website with updated (after proposal) information. Please send your GitHub ID’s to Gregor laszewski@gmail.com so he can enable to directly edit web site
- Only Gregor contributed so far with core site https://sbi-fair.github.io/
- Not all GitHub invitations have been accepted
- Deborah Penchoff of UTK identified a template for DOE annual report. We should accumulate the needed contributions
- We agreed to set the next meeting for 1-2 pm Eastern May 24 2021 at the usual zoom https://iu.zoom.us/j/2301429329
8.32 - Meeting Notes 03-23-2021
Meeting Notes from 03-23-2021
Minutes of Meeting March 23 2021
Links for Today’s Meeting
- Argonne Update Presentation SBI- ANL-202103-Updates
- Argonne Surrogate Application SBI-ANL-202103-Ptycho-Surrogate.pptx
- Tennessee Update Presentation SBI @ UTK 2k21
- Indiana University Update Presentation SBI-Meeting-IU-Mar23-2021
- Christine Kirkpatrick’s MLCommons Science working group talk on FAIR Metadata mlcommons_fair_0221.pptx
- Compilation of MLCommons logged metadata Logging Info MLCommons
The 4 sites all gave updates with presentations listed above.
Indiana largely discussed work with MLCommons Science research working group
- Benchmark collection which will eventually include surrogates
- Benchmark Technology and FAIR metadata
Argonne presented substantial progress with
- The hiring of a new postdoc Xiaodong Yu with substantial experience
- Identification of several surrogates including those that don’t work e.g. give insufficient accuracy
- Use of ThetaGPU
**Tennessee **reported substantial progress with
- Examination of MLFlow and its metadata which support many storage formats but are missing FAIR features
- ONNX Open Neural Network Exchange which currently has no science or surrogate examples
- The N to N issues of matching many inputs to many outputs’
- Performance surrogate model for Autotuning work in progress
Rutgers (no presentation) discussed two activities
- Effective performance where a new student will join.
- Surrogates corresponding to two Gordon Bell prize winners at SC20 extending from Rutgers work with Argonne (autoencoders for collective coordinates to move through phase space quickly) to the other winner from Princeton where AI learned the complex potential.
Action Items
- We agreed to set the next meeting for 1-2 pm Eastern April 19 2021 at the usual zoom https://iu.zoom.us/j/2301429329
- We agreed to enhance the web site with updated (after proposal) information. Please send your GitHub ID’s to Gregor laszewski@gmail.com so he can enable to directly edit web site
- Shantenu agreed to coordinate a surrogate working group after 4 weeks
- Piotr agreed to coordinate cross-institution FAIR activities including issues of MLCommons metadata and Christine Kirkpatrick’s work
- Argonne will investigate Yu giving a short presentation
8.33 - Meeting Notes 02-20-2021
Meeting Notes from 02-20-2021
University of Tennessee Knoxville
- Deborah Penchoff joining the team
- UTK Schema
- MLFlow – reproducibility
- Is training repeatable
- Need to have a group on this
- UTK have their own surrogates science and performance
- Storage
- Uq
- Hardware
Rutgers University
- Performance of surrogates
- What does it mean
- Gordon bell prizes
- Deepdrivemd greatly advanced
- Working with Princeton Gordon Bell
- 2 billion paper
Argonne National Laboratory
Clear plans
Candle
Paper creates a surrogate howto – GCF forgets this
DOE_FAIR2020-Surrogates
Github site infrastructure
Web site built on Github - Possible Hugo web site
Form Google group
Form working groups
Infrastructure & Benchmarking Tech
Metadata/FAIR
Surrogates
All meet once a month
8.34 - Meeting Notes 01-20-2021
Meeting Notes from 01-20-2021
**Indiana University **
Report SBI-Meeting-IU-Jan20-2021
University of Tennessee Knoxville
Report SBI @ UTK 2k21
Deborah Penchoff joining the team
UTK Schema
MLFlow – reproducibility
Is training repeatable
Need to have a group on this
UTK have their own surrogates science and performance
Storage
Uq
Hardware
Rutgers
**Report **SBI-Rutgers Jan 20-2021
Performance of surrogates
What does it mean
Gordon bell prizes
Deepdrivemd greatly advanced
Working with Princeton Gordon Bell
2 billion paper
Argonne
Report SBI-Meeting-IU-Jan20-2021
Clear plans
Candle
Paper creates a surrogate howto – GCF forgets this
Github site infrastructure
Web site built on Github - Possible Hugo web site
Form Google group
Form working groups
Infrastructure & Benchmarking Tech
Metadata/FAIR
Surrogates
All meet once a month
9 - Contribution Guidelines
How to contribute to the docs
More informatio nwill be here soon …
The Web Site is hosted on Github and can be modified with pull requests.
To edit the About page, use these links: